
关键要点
- 对于大规模视频流数据的可靠处理和高效处理,需要可扩展、容错和松散耦合的分布式系统。
- 本文中的示例应用程序使用开源技术——OpenCV、Kafka 和 Spark——来构建这样一个系统。Amazon S3 或 HDFS 可用于存储.
- 该系统包括三个主要组件——视频流收集器、流数据缓冲器和视频流处理器。
- 视频流收集器工作带有一组 IP 摄像机,它们提供视频内容流数据的实时馈送,并使用 OpenCV 视频处理库将视频流转换为帧,将 JSON 中的数据传递给用于 Stream Data Buffer 组件的 Kafka Broker。
- Video Stream Processor 组件基于 Apache Spark 构建,并再次使用 OpenCV 处理视频流数据。
技术给非结构化数据带来了前所未有的爆炸式增长。移动设备、网站、社交媒体、科学仪器、卫星、物联网设备和监控摄像头等来源每秒都会生成大量图像和视频。
管理和有效分析这些数据是一项挑战。考虑一个城市的视频监控摄像头网络。监视每个摄像机的视频流以发现任何感兴趣的对象或事件是不切实际且低效的。相反,计算机视觉 (CV) 库处理这些视频流并提供智能视频分析和对象检测。
然而,传统的 CV 系统有局限性。在传统的视频分析系统中,带有 CV 库的服务器同时收集和处理数据,因此服务器故障会丢失视频流数据。检测节点故障并将处理切换到另一个节点可能会导致数据碎片化。
许多任务推动了大数据技术在视频流分析中的使用:大规模视频流的并行和按需处理,从视频帧中提取不同的信息集,使用不同的机器学习库分析数据,管道传输分析数据到应用程序的不同组件进行进一步处理,并以不同格式输出处理后的数据。
视频流分析 – 运动检测
为了可靠地处理和高效处理大规模视频流数据,需要一个可扩展的、容错的、松散耦合的分布式系统。本文中讨论的视频流分析就是根据这些原则设计的。
视频流分析的类型包括:
- 对象跟踪,
- 运动检测,
- 人脸识别,
- 手势识别,
- 增强现实,以及
- 图像分割。
本文示例应用程序的用例是视频流中的运动检测。
运动检测是发现物体(通常是人)相对于其周围环境的位置变化的过程。它主要用于持续监控特定区域的视频监控系统。CV 库提供的算法分析此类摄像机发送的视频源并查找任何运动。检测运动会触发一个事件,该事件可以向应用程序发送消息或提醒用户。
本文的视频流分析应用程序具有三个主要组件:
- 视频流收集器,
- 流数据缓冲区,
- 视频流处理器。
视频流收集器从一组 IP 摄像机接收视频流数据。该组件将视频帧序列化到流数据缓冲区,这是一个用于流视频数据的容错数据队列。视频流处理器消耗来自缓冲区的流数据并对其进行处理。该组件将应用视频处理算法来检测视频流数据中的运动。最后,处理后的数据或图像文件将存储在S3 存储桶或HDFS目录中。该视频流处理系统是使用OpenCV、Apache Kafka和 Apache Spark框架设计的。
OpenCV、Kafka和Spark的简要细节
以下是相关框架的一些细节。
OpenCV
OpenCV(开源计算机视觉库)是一个开源的 BSD 许可库。这个库是用 C++ 编写的,但也提供了 Java API。OpenCV 包含数百种 CV 算法,可用于处理和分析图像和视频文件。请查看此文档 以获取更多详细信息。
Apache Kafka
Apache Kafka 是一个分布式流媒体平台,它提供了用于发布和订阅记录流的系统。这些记录可以以容错的方式存储,消费者可以处理数据。
Apache Spark
Apache Spark 是一个快速、通用的集群计算系统。它提供了用于 SQL 和结构化数据处理的模块、用于机器学习的 MLlib、用于图形处理的 GraphX 和 Spark Streaming。
系统架构
视频流分析系统的架构图如下图1所示。
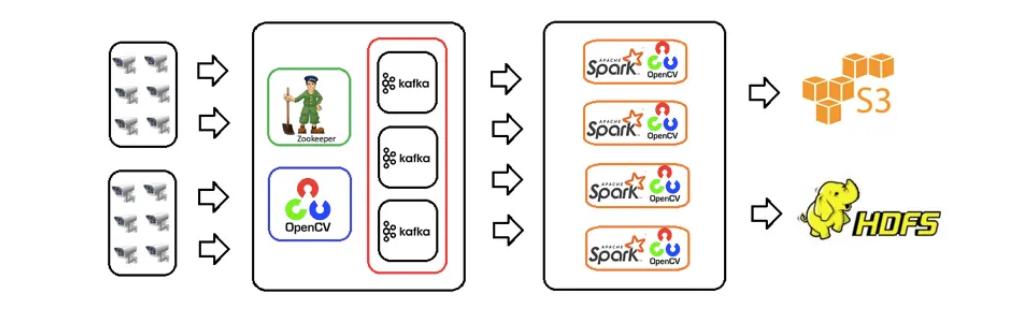
图 1. 视频流分析系统架构图
设计与实施
以下部分提供了示例应用程序中视频流收集器、流数据缓冲区和视频流处理器的设计和实现细节。
视频流收集器
视频流收集器与一组提供实时视频馈送的 IP 摄像机配合使用。该组件必须从每个摄像头读取提要并将视频流转换为一系列视频帧。为了区分每个 IP 摄像头,采集器维护了摄像头 ID 和 URL 的映射关系相机网址和相机.ida中的属性流收集器.properties文件。这些属性可以具有以逗号分隔的相机 URL 和 ID 列表。不同的相机可以提供不同规格的数据,例如编解码器、分辨率或每秒帧数。收集器在从视频流创建帧时必须保留这些细节。
视频流收集器使用 OpenCV 视频处理库将视频流转换为帧。每个帧都被调整为所需的处理分辨率(例如 640×480)。OpenCV 将每个帧或图像存储为一个Mat对象。Mat 需要通过保持帧的详细信息(即行、列和类型)完整地转换为可串行化(字节数组)形式。视频流收集器使用以下 JSON 消息结构来存储这些详细信息。
{"cameraId":"cam-01","timestamp":1488627991133,"rows":12,"cols":15,"type":16,"data":"asdfh"}
cameraId是相机的唯一 ID。timestamp是生成帧的时间。rows, cols,并且type是 OpenCV Mat 特定的细节。data是帧的字节数组的 ba?se-64 编码字符串。
视频流收集器使用Gson库将数据转换为 JSON 消息,在video-stream-event主题中发布。它使用KafkaProducer客户端将 JSON 消息发送到 Kafka 代理。KafkaProducer 将每个 key 的数据发送到同一个分区,并保证这些消息的顺序。
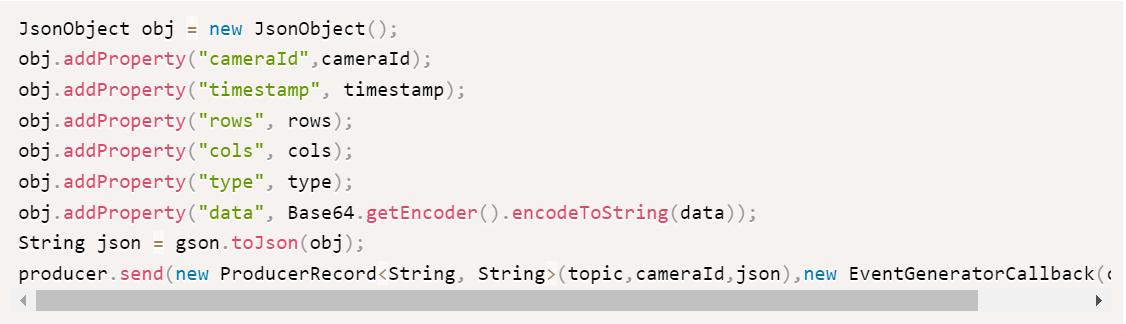
图 2. 将图像作为 JSON 消息发送的代码片段
Kafka 主要是为小尺寸的文本消息设计的,但是包含视频帧的字节数组的 JSON 消息会很大(例如 1.5 MB),因此 Kafka 需要更改配置才能处理这些较大的消息。需要调整以下 KafkaProducer 属性:
- batch.size
- max.request.size
- compression.type
流数据缓冲区
为了不丢失地处理大量视频流数据,需要将流数据存储在临时存储器中。Kafka 代理充当视频流收集器生成的数据的缓冲队列。Kafka 使用文件系统来存储消息,并且保留这??些消息的时间长度是可配置的。
在处理之前将数据保存在存储中可确保其持久性并提高系统的整体性能,因为处理器可以根据负载在不同时间以不同速度处理数据。当数据生产速度超过数据处理速度时,这提高了系统的可靠性。
Kafka 保证给定主题的单个分区中的消息顺序。当数据的顺序很重要时,这对于处理数据非常有帮助。要存储大消息,可能需要在server.propertiesKafka 服务器的文件中调整以下配置:
- message.max.bytes
- replica.fetch.max.bytes
视频流处理器
视频流处理器执行三个步骤:
- 以数据集的形式从 Kafka 代理读取 JSON 消息VideoEventData。
- 按摄像机 ID对数据集进行分组VideoEventData并将其传递给视频流处理器。
- 从 JSON 数据创建一个 Mat 对象并处理视频流数据。
视频流处理器基于 Apache Spark 构建。Spark 提供了一个Spark Streaming API,它使用离散化流或 DStream,以及一个新的Structured Streaming基于数据集的 API。此应用程序的视频流处理器使用结构化流 API 来使用和处理来自 Kafka 的 JSON 消息。请注意,此应用程序以 JSON 消息的形式处理结构化数据,非结构化视频数据是视频流处理器将处理的这些 JSON 消息的属性。Spark 文档指出“结构化流式处理提供了快速、可扩展、容错、端到端的一次性流处理,而用户无需对流式处理进行推理。” 这就是为什么视频流处理器是围绕 Spark 的结构化流设计的。结构化流引擎为结构化文本数据和聚合查询的状态管理提供内置支持。
要处理大消息,必须将以下 Kafka 消费者配置传递给 Spark 引擎:
- max.partition.fetch.bytes
- max.poll.records
该组件的主要类是VideoStreamProcessor. 此类首先创建一个SparkSession对象,该对象是使用 Spark SQL 引擎的入口点。下一步是为传入的 JSON 消息定义一个模式,以便 Spark 可以使用该模式将消息的字符串格式解析为 JSON 格式。Spark 的 bean 编码器可以将其转换为Dataset<VideoEventData>. VideoEventData是一个保存 JSON 消息数据的 Java bean 类。
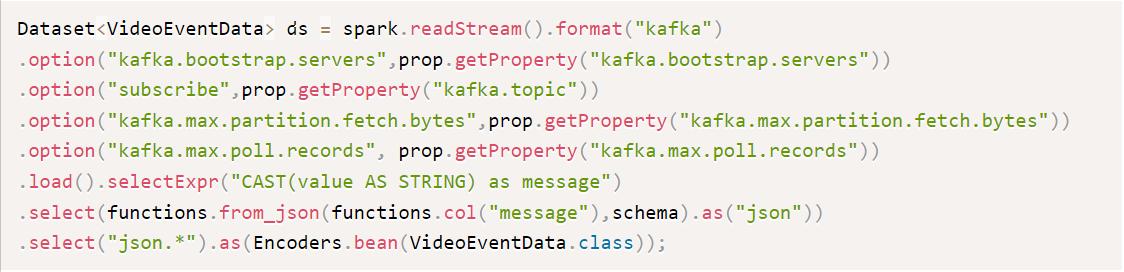
图 3. Spark Streaming 处理 kafka 消息的代码片段
下一个,groupByKey按相机 ID 对数据集进行分组以获取KeyValueGroupedDataset<String, VideoEventData>. 它使用一个mapGroupsWithState转变为一组工作视频事件数据(迭代器<VideoEventData>) 用于按摄像机 ID 分组的当前批次视频帧。此转换首先检查最后处理的视频事件数据(视频帧)存在并将其传递给视频处理器进行下一步处理。视频处理后,最后处理的视频事件数据(视频帧)从视频处理器返回并更新状态。要启动流媒体应用程序,写流使用控制台接收器和更新输出模式在数据集上调用方法。
视频流处理器使用 OpenCV 库来处理视频流数据。我们的应用程序旨在检测运动;视频运动检测器是具有用于检测一系列帧中的运动的逻辑的类。这个过程的第一步是对列表进行排序视频事件数据(迭代器<VideoEventData>) 通过给定摄像机 ID 的时间戳来按顺序比较视频帧。下一步是迭代排序的列表视频事件数据对象并将它们转换为 OpenCV垫目的。如果最后处理的视频帧可用,则它将其用作处理当前帧系列的第一个视频帧。视频运动检测器比较两个连续的帧并使用 OpenCV 库提供的 API 检测差异。如果它发现超出定义标准的差异,则将其视为运动。视频运动检测器将以图像文件的形式将此检测到的运动保存到预配置的 S3 存储桶或 HDFS 目录。此图像文件可以由另一个应用程序进行进一步处理,或者视频运动检测器可以触发事件以通知用户或应用程序已检测到运动。
技术和工具
下表显示了用于此视频流分析系统的技术和工具。
|
工具和技术 |
版本 |
下载网址 |
|
JDK |
1.8 |
http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html |
|
Maven |
3.3.9 |
https://maven.apache.org/download.cgi |
|
ZooKeeper |
3.4.8 |
https://zookeeper.apache.org/releases.html |
|
Kafka |
2.11-0.10.2.0 |
http://kafka.apache.org/downloads.html |
|
Spark |
2.2.0 |
http://spark.apache.org/downloads.html |
|
OpenCV |
3.2.0 |
http://opencv.org/releases.html |
请参阅有关安装和配置这些工具的文档。Kafka 文档和Spark 文档提供了有关如何在独立模式或集群模式下设置和运行应用程序的详细信息。要安装 OpenCV,请参阅OpenCV 文档。
构建和部署
本节详细介绍如何构建和运行示例应用程序的视频流收集器和视频流处理器组件。此应用程序可用于处理离线视频文件和实时摄像机源,但此处配置为分析离线示例视频文件。请按照以下步骤构建和运行此应用程序:
1.下载并安装上表中列出的工具。确保 ZooKeeper 和 Kafka 服务器已启动并正在运行。
2.此应用程序使用 OpenCV 本地库(.dll 或 .so)并使用该System.loadLibrary()方法加载它们。在系统环境变量中设置这些本机库的目录路径或将此路径作为命令行参数传递。例如,对于 64 位 Windows 机器,本机库文件(opencv_java320.dll 和 opencv_ffmpeg320_64.dll)的路径将为 {OpenCV 安装目录}\build\java\x64。
3.该stream-collector.properties文件的 Kafka 主题为video-stream-event. 在 Kafka 中创建此主题和分区。使用该kafka-topic命令创建主题和分区。
kafka-topics.sh –create –zookeeper localhost:2181 –topic video-stream-event –replication-factor 1 –partitions 3
4.stream-processor.properties文件有一个processed.output.dir属性,就是保存处理过的图片的目录路径。创建并设置此属性的目录路径。
5.stream-collector.properties文件具有camera.url保存视频文件或视频源的路径或 URL 的属性。确保路径或 URL 正确。
6.检查log4j.properties文件VideoStreamCollector和组件,并VideoStreamProcessor设置文件的目录路径。检查这些日志文件以获取应用程序生成的日志消息,这有助于在运行应用程序时出现错误。stream-collector.logstream-processor.log
7.此应用程序使用 OpenCV JAR 文件中的 OpenCV API,但 OpenCV JAR 文件在 Maven 中央存储库中不可用。此应用程序与可安装到本地 Maven 存储库的 OpenCV JAR 文件捆绑在一起。在 pom.xml 文件中,maven-install-plugin已配置并与用于安装此 JAR 文件的 clean 阶段相关联。要在本地 Maven 存储库中安装 OpenCV JAR,请转到 video-stream-processor 文件夹并执行此命令。
mvn clean
8.为保持应用程序逻辑简单,VideoStreamProcessor 只处理新消息。在启动组件之前,该VideoStreamProcessor组件应该已启动并运行VideoStreamCollector。要VideoStreamProcessor使用 Maven 运行,请转到 video-stream-processor 文件夹并执行此命令。
mvn clean package exec:java -Dexec.mainClass="com.iot.video.app.spark.processor.VideoStreamProcessor"
9.VideoStreamProcessor启动后,启动VideoStreamCollector组件。转到 video-stream-collector 文件夹并执行此命令。
mvn clean package exec:java -Dexec.mainClass="com.iot.video.app.kafka.collector.VideoStreamCollector" -Dexec.cleanupDaemonThreads=false
GitHub 项目捆绑了一个 sample.mp4 视频文件。此视频文件的 URL 和 ID 已配置为stream-collector.properties 文件的属性camera.url。camera.id处理完视频文件后,图像将保存在预先配置的目录中(步骤 4)。图 4 显示了此应用程序的示例输出。

图 4. 运动检测的示例输出
此应用程序可以配置和处理多个视频源(离线和实时源)。例如,要与 sample.mp4 一起添加网络摄像头供稿,请编辑 stream-collector.properties 文件并在属性中添加整数(第一个网络摄像头为 0,第二个网络摄像头为 1,依此类推),camera.url并添加相应的摄像头ID(cam-01、cam-02 等)在camera.id属性中用逗号分隔。这是一个例子:
camera.url=../sample-video/sample.mp4,0
camera.id=vid-01,cam-01
结论
视频流的大规模视频分析需要一个由大数据技术支持的强大系统。OpenCV、Kafka 和 Spark 等开源技术可用于构建用于视频流分析的容错分布式系统。我们使用 OpenCV 和 Kafka 构建了一个视频流收集器组件,用于接收来自不同来源的视频流并将它们发送到流数据缓冲区组件。Kafka 充当流数据缓冲区组件,提供流数据的持久存储。视频流处理器组件是使用 OpenCV 和 Spark 的 Structured Streaming 开发的。该组件从流数据缓冲区接收流数据并分析该数据。处理后的文件存储在预配置的 HDFS 或 S3 存储桶中。我们使用运动检测作为用例来演示视频流分析示例应用程序。


如若转载,请注明出处:https://www.daxuejiayuan.com/9333.html
相关推荐
-
文学门户网站有哪些(大家读书院 – 网络文学门户)
良言一句三冬暖,妙方一招四季安。 因为一场病,导致我的身体健康出现状况 从而体质下降,连续十多年经常性感冒吃药打 针。 一 次偶然的发现,触动了我的心灵,从而 改变了我的整个人生。…
-
免费个人网站建站(网络免费建站)
wordpress好用的插件推荐,为什么要用wordpress插件,因为wordpress插件能让我们的网站拥有更多的功能,今天给大家推荐的wordpress插件一个插件多个功能支…
-
text一sym李颜控. com网站ols一com网站(李颜控. com网站)
本文来自《浪潮三十年》之 第六章 1999 世纪狂欢 未经容许 请勿转载 前文提到了陈天桥找中华网投资的故事,1999年的中华网可谓如日中天,他有个响亮的域名china.com。据…
-
本地o2o同城(本地o2o平台政策)
自从1980年我国掀起了第一波创业潮后,现在我们正在经历第二波创业狂潮,在第一波创业潮时,互联网创业的条件很差、互联网创业的环境很差、互联网创业的人很少,但那时创业成功的人都已经成…
-
食品生产许可证查询入口(江苏省食品生产许可证查询)
好消息!好消息!无锡经开区全面推行食品经营许可证全流程网上办理啦!无须前往服务大厅,直接线上申办。 为进一步提升行政审批服务效率,让群众能够更便捷地办理食品审批业务,江苏省市场监督…
-
张家口家银易支付下载(首信易支付下载)
大家好,我是一个喜欢各种研究,各种倒腾的人,今天给你们分享一个影视系统,这个影视系统带H5功能,开源的程序,不需要授权,有技术的小伙伴可以自己开发,这个名字我想大家看图就知道了,千…
-
阳光软件是个什么(阳光软件是谁发明的)
哈喽大家好呀,我是分享科技小达人。 今天是一期手机APP分享,给大家精挑细选整理了整理了5款好用的APP,一起来看看吧~ ?01.Canva可画 可画是一款好用的海报/PPT/简历…
-
整站营销系统(整站seo技术)
咱们营销人会习惯性思考每一个营销动作背后的逻辑,为什么会有直播?为什么会有海报?如果你再结合其他品牌触点上的营销动作,很快就会在脑海中产生一个疑问,这些营销触点整体是如何分布的,而…
-
页游源码免费下载(页游源码怎么架设)
手游届里这两天又闹一乌龙,刚上线一天就停服。我说的可不是《终焉誓约》,终焉誓约我甚至游戏都没有进去,就延迟开服了。 今天就来说说昨天公测的一款游戏《奥特曼集结》,之前有一次测试,是…
-
润色文章网站(投稿文章网站)
本期的内容:今天我分享五个金句文案网站,简单、实用、免费,能够快速提升你的写作水平,提高文章质量,写出优质的爆款文章。让你在视频里金句频出,妙语连珠。 看完这文章,你再也不用发愁找…
