
BFS 和 DFS 实现

DAG 的拓扑排序是其节点的部分线性排序,因此如果该图有一条从 u 指向 v 的边,则 u 应该放在 v 之前的排序中。部分排序在许多情况下非常有用。调度问题,依赖解决方案。
一些有用的图表术语
- indegree – 指向它的边数。
- outdegree – 从顶点向外延伸的边数。
- Source Vertex — 没有边指向它的顶点。它的边缘只指向外面。
- Sink Vertex — 没有出边的顶点。它的边缘只指向它。
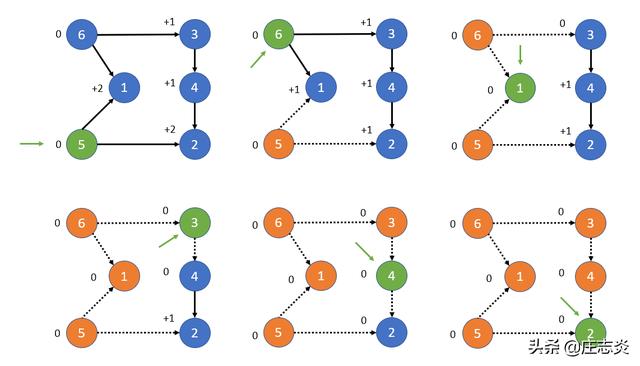
卡恩算法 (BFS)
脚步
- 将所有节点的入度存储在图中。
- 识别入度为 0 的节点。将每个节点添加到将被迭代的队列中。
- 当包含入度为 0 的节点的集合不为空时,删除一个节点。将节点存储在结果列表中。对于移除的每个节点,迭代其边缘,递减边缘上每个目标节点的入度。如果一个节点现在的入度为 0,则按照步骤 2 将其添加到队列和列表中。
- 最后,返回每个节点附加到的列表。这将包含节点的拓扑排序。
代码实现
from collections import defaultdict
class Graph:
def __init__(self, vertices):
self.graph = defaultdict(list)
self.V = vertices def add_edge(self, u, v):
self.graph[u-1].append(v-1) def topological_sort(self):
in_degree = [0]*(self.V)
visited = [0]*(self.V)
for i in self.graph:
for j in self.graph[i]:
in_degree[j] += 1
top_order = []
queue = []
from heapq import heappush, heappop
for i in range(self.V):
if in_degree[i] == 0:
heappush(queue, i) while queue:
u = heappop(queue)
if not visited[u]:
top_order.append(u+1)
for i in self.graph[u]:
in_degree[i] -= 1
if in_degree[i] == 0:
heappush(queue, i)
visited[u] = 1
return top_order## Driver code
A = 6
B = [[6, 3], [6, 1], [5, 1], [5, 2], [3, 4], [4, 2]]graph = Graph(A)
for u, v in B:
graph.add_edge(u, v)
res = graph.topological_sort()
print(res) # [5, 6, 1, 3, 4, 2]在上面的实现中,我使用了 heapq,因为我想确保结果在字典上是最小的,以防我们有多个订单。 另外,我使用了(u-1 和 v-1),因为我使用的是基于 1 的节点索引。
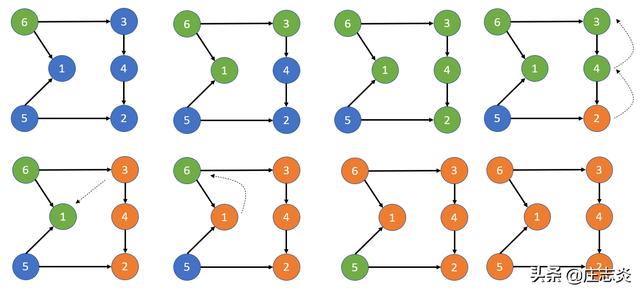
改进的深度优先搜索
脚步
- 从任何顶点开始并在其上调用 DFS 函数。
- 继续沿着该路径遍历,直到找到一个没有进一步出边的节点。
- 将其添加到拓扑排序中(我们将其插入堆栈中第 0 个索引处,否则我们将获得相反的顺序)。
- 回溯到具有更多未访问后代的前一个节点。
- 继续,直到您访问了所有节点。
代码实现
from collections import defaultdict
class Graph:
def __init__(self, vertices):
self.graph = defaultdict(list)
self.V = vertices
def add_edge(self, u, v):
self.graph[u-1].append(v-1) def helper(self,u,visited, res):
visited[u] = True
for i in self.graph[u]:
if visited[i] == False:
self.helper(i, visited, res)
res.insert(0, u+1) def topological_sort(self):
visited = [False]*self.V
res =[]
for i in reversed(range(self.V)):
if visited[i] == False:
self.helper(i, visited, res)
return res## Driver code
A = 6
B = [[6, 3], [6, 1], [5, 1], [5, 2], [3, 4], [4, 2]]
graph = Graph(A)
for u, v in B:
graph.add_edge(u, v)
res = graph.topological_sort()
print(res) # [5, 6, 1, 3, 4, 2]在上面的实现中,我使用了 reversed(range(self.V)) ,因为我想确保结果在字典上是最小的,以防我们有多个订单。
快乐编码!
关注七爪网,获取更多APP/小程序/网站源码资源!


如若转载,请注明出处:https://www.daxuejiayuan.com/38808.html
相关推荐
-
论坛是什么意思啊(什么是论坛,怎么逛论坛)
烟雨西湖醉朦胧、翠竹流水暖清风。相约盛夏时节,第十六届规划和自然资源信息化实务论坛即将如约而至!今年论坛又引入全新玩法啦——互动社群!在这个畅所欲言的线上平台,你不仅可以实时收获论…
-
网人(网贷逾期还不上怎么办有什么后果)
老大笑道: “得啦,别再一心二用了,早些将这套阴阳剑法练熟,师父自然会令咱们下山,否则,尽在心里想媳妇儿也没用,十年都过了,何况这几天呢!” 老二笑笑,没再开口,两人各举长剑,…
-
asp虚拟空间(虚拟空间应用)
来源:内容由半导体行业观察(ID:icbank)综合自Yole,谢谢。 虽然上海的疫情防控给汽车带来了一些杂音,但汽车销售正受益于疫情后的激增——人们可以称之为重生,而不是反弹。 …
-
网络游戏开源机制(网络游戏开源软件)
开源并不仅仅指的是软件。开源是一种文化现象,自然也适合桌面游戏。 我喜欢优秀的游戏,尤其是桌游,因为桌游的很多特性都和开源相同。在现实生活中,当你和朋友围坐在桌旁一起玩卡牌游戏时,…
-
磁力风(理财和科创的碰撞!新津成外学子秒变“商界大佬”和“科技达人”)
来咯!来咯! 新津成外第二届理财&美食节暨首届科创节来咯! 开篇 同学们来到操场上,纷纷展出自己的开店广告牌,队伍排列整齐划一,每个人都雄赳赳气昂昂,仿佛自己就是这个世界上…
-
原型设计工具,(原型设计工具有哪些_)
戳“阅读原文”我们一起进 四款产品经理最常用的原型图工具 Axure:https://www.axure.com.cn/ 墨刀:https://modao.cc/ 摹客:https…
-
淘宝客源码 开源(淘宝客源码最新)
英深网建站 www.gxyings.com 一、效果说明 建站网站可以支持包括百度网盟、淘宝客、凡客诚品等在内的许多CPA(CPS等)类的广告代码,包括html,js等类型,还…
-
婷婷电影网(笑话惹的祸(上))
生活孤燥无味,开开玩笑也挺好!这个闹笑话呀,也得有分寸,你要是没了分寸,闹过了火儿了,那都能出人命啊。说有这么一个屯子,住着一户姓耿的人家,就哥俩儿,爹妈都死了,这老大呀,有25-…
-
抖音如何注销自己的账号,(抖音如何注销自己的账号多久消失)
自从有了抖音,视频号,自己的闲暇时光几乎都被花在了这些短视频上,一两个小时一转眼就没了。 有人说,成年后,人与人之间差距的逐渐拉开就取决于我们每天工作之余的零散时间,是用来干什么的…
-
soNAS太复杂!影库+远程下载帮你搞定影音库t磁力(NAS太复杂!影库+远程下载帮你搞定影音库)
如果说这几年在数码圈里比较火的玩机设备有哪些? NAS肯定是其中一个。 毕竟想打造私人影音库,很多人都认为目前相对完美的搭配是:NAS+播放器软件。 什么是NAS?随着时代的变迁与…