
为什么需要编码?
原始视频数据很庞大,比如一个150分钟,30FPS,分辨率为720?480的彩色电影需要占用280GB。无论是物理存储还是网络传输,这都是难以负担的。所以需要编码进行压缩。
编码方式
一般有两种编码方式:熵编码(entropy coding,以无损的方式将视频压缩到香农极限)和有损编码(lossy coding,删除冗余数据和不重要的数据)。熵编码的压缩率是有限的,但是得益于人类的视觉系统可以容忍细节丢失,有损压缩通常很有效。
典型的编解码码流程
下图展示了编解码的整体流程。 摄像头采集到数据,进行编码,传输或者保存编码后的数据,终端拿到数据后进行解码并显示。


下图展示了一个典型的编码流程:
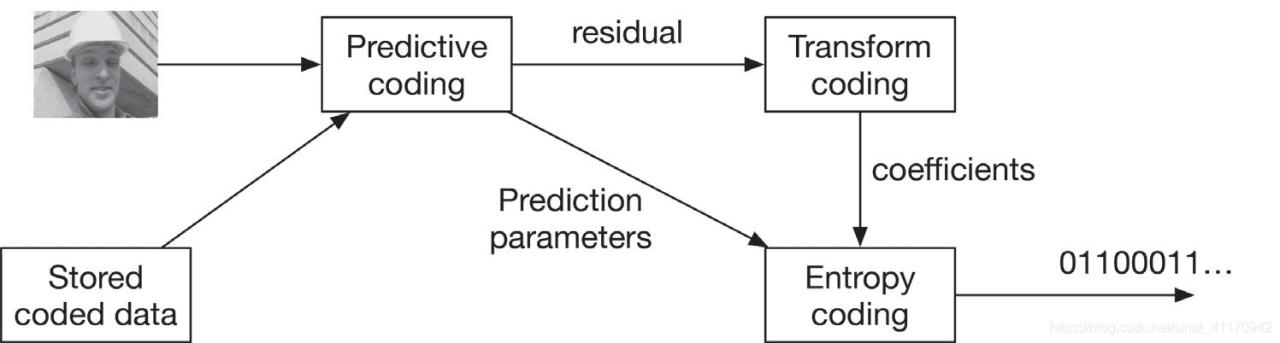
一个典型的视频编码一般由三个模块组成:
预测性编码(Predictive coding)
转换编码(Transform coding)
熵编码(Entropy coding)
通常编码一个视频会产生若干完整的帧数据和增量帧数据。
完整帧只需要通过转换编码和熵编码进行压缩。本文主要考虑增量帧的编解码。
领取C++音视频开发学习资料:点击→音视频开发(资料文档+视频教程+面试题)(FFmpeg+WebRTC+RTMP+RTSP+HLS+RTP)
预测性编码
预测性编码通过利用时间(帧间预测)和空间冗余(帧内预测)来减少视频的冗余度。
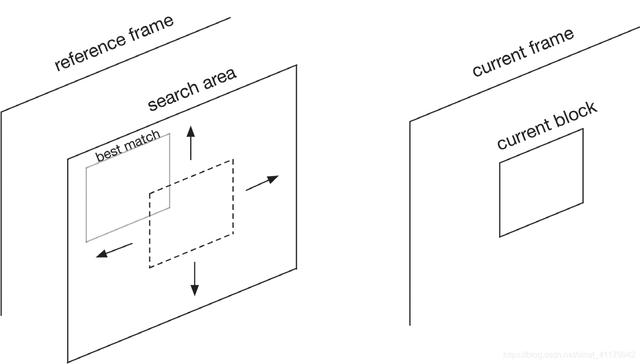
通常预测性编码有两步:运动估计(Motion estimation, ME)和运动补偿(Motion compensation, MC)
运动估计为当前帧的某个区域(A)在参考帧中寻找一个合适的匹配区域(B)。(参考帧可以是之前的帧,也可以是后面的帧)
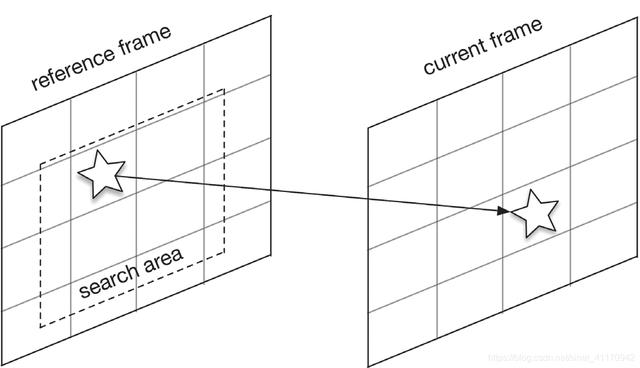
运动补偿找到区域A和区域B的不同
通过ME和MC预测性编码会产生一些运动矢量和残差。运动矢量就是某些区域针对参考帧的运动轨迹,而残差就是这些区域运动后产生的预测帧和当前帧之间的不同。举个不太恰当的例子:(不恰当的地方在于真实的编码中运动矢量涉及的区域不会这么大,比如H.264编码的最大区域为16?16)
下象棋时,开局时为参考帧,炮二平五后为当前帧,如图:
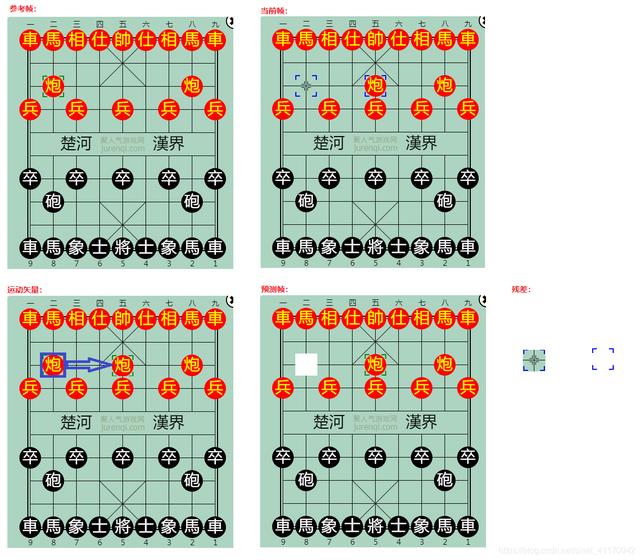
这时运动矢量就是炮二的区域移动到炮五的区域,移动后产生一个预测帧。预测帧和当前帧并不完全一样,他们的区别就是残差。
此时的残差则是炮二位置的棋格,以及炮五边框的颜色变化。
预测性编码的产出就是这些运动矢量和残差,通过这个例子我们能看到这些产出数据是远远小于一个完整帧的数据量的。
转换编码(有损压缩)
转换编码模块的产出是一组系数,每个系数是标准基础图案的权重。 通过量化器之后,可获得降低精度但节省位的量化系数。
反过来标准基础图案使用这些量化系数可以得到量化前的图案。
例如,1974年开发的离散余弦变换(DCT)是一种广泛使用的变换编码技术。 H.264编码就是将残差通过转换编码转换为DCT系数。
详细流程就不赘(知)述(道)了。。
基本原理利用了傅里叶变换思想(使用一些正余弦公式表示图像)
下面的公式中,y为编码前的图案,x为标准基础图案数据,f(x)是一个公式里面会涉及一组系数k,这一组k就是转换编码的输出。
y≈f(x)=k1f1?(x)+k2?f2?(x)+…+kn?fn?(x)
一个16?16的图案,大概需要80个系数就足够了,这时的压缩率为31.25%
熵编码(无损压缩)
将前面得到的所有数据进行压缩,包括运动矢量、残差的量化系数、还有预测性编码的一些参数。
常见的熵编码方法包括可变长度编码(VLC),算术编码和霍夫曼编码。
以大家最熟悉的霍夫曼编码为例,它根据数据出现的频率对数据进行编码,频率高的编码后的长度短,频率低的编码后的长度长。
解码
编码流程的逆序就是解码流程。
解码器拿到编码后的数据后:
根据熵编码的类型,将压缩的数据展开,得到转换编码数据(运动矢量、残差的量化系数、还有预测性编码的一些参数)
根据残差的量化系数,得到残差数据
在参考帧的基础上,实施这些运动矢量,产生预测帧
在预测帧的基础上,叠加残差数据,得到当前帧


如若转载,请注明出处:https://www.daxuejiayuan.com/37115.html
相关推荐
-
chengrenpian(成人便便是黑色的怎么回事)
北欧电影,经常给人带来一种怪诞的“自然感”。 它从不解释恶为什么会存在、是如何形成的,仿佛那就是生命的一部分,与自然万物同生共息。 由此,北欧电影也爱把有“问题”的人异化为动物。 …
-
苍背银猿
可是面对苍背银猿,情况就有些不同了。 灾厄级的苍背银猿,和李奥的剑侠是在同一等级的。 光论身体能力和身体素质,苍背银猿超出了李奥一大截,就算是绝大多数的九阶战士都比不了。这…
-
微群管家,(微群管家官方免费下载)
来源:【沈阳日报-沈阳网】 “通过网格微信群,居民们能够及时得知最新的疫情相关信息,生活上遇到问题也能在第一时间向社区反映并得到解决。群里还经常发送反电诈案例和提醒,可以随时提醒大…
-
背着奶奶进城演员表(背着奶奶进城剧情介绍)
好像从来没有听说过奶奶爸妈的故事,或许是太过久远,又或许是没有什么值得忆起的过往,以致于在我的记忆中,没有任何关于奶奶其他亲人零星的印记。 奶奶今年已经八十多了,和爷爷一共养育了六…
-
竞技类小说天花板,书荒的友友们快来领取你们的周末福利吧
大家好,我是武横游戏放松身心,体育竞技使人热血沸腾,今天带来的小说是二者结合版,在看的同时让你感受到既有游戏的体验又有看体育比赛的那种激情。每一本都是高分作品,接下来就让我们一起进…
-
cms系统(cmsv6监控)
通过两个不同的音叉本体及相同的音叉把手子结构,讲述了如何在Ansys Workbench中快速完成基于模态综合法的动力学分析。2022 R1中的这个新功能比起传统在经典界面下的操作…
-
td阅读挑战(td阅读是什么意思啊)
“ 姐姐,姐姐……”西施被一声声熟悉的呼唤叫醒。她慢慢睁开眼睛,朦胧中看见东施坐在身边。西施甚感诧异。她以为自己仍在做梦。最近,她老是这样恍恍惚惚。自从几天前被那些人强行破了身,她…
-
炒股博客新浪排名(炒股博客个股)
回头看看,进入股市已经五六年了,从开始的满腔热血,赚了几百块就兴高采烈的小白,到亏几万也装作满不在乎的老白。 时间悄悄溜走,也带走了刚入场时的热情,几年下来,基本上不赚不亏,技术也…
-
百度怎么刷,(百度怎么刷新)
百度问一问服务者可以提供自己擅长领域的付费问答服务,我也申请开通为答主体验了一下。 一、答主开通流程 百度APP-?我的-?“答主中心”或者“问一问”,申请成为答主选择对应的领域。…
-
公司网站源码去一品资源(建站公司网站源码)
网站不比实体商品那样,有固定成本及固定价格。说白了它就是虚拟的。一个网站可以像上面几万来做,也可以几百就搞定。一旦签订合同,是没有反悔的。市场有很多不懂网站开发行情的小白,要是碰到…