
前言
大家好,我是小六,上一篇文章主要是最近在总结前端的面试,记录下来的一些大厂的面试题,看大家都那么喜欢,我决定再来一篇!大家觉得还可以的话,请大家务必点赞、收藏或者转发保存下,后面我总结成电子文档,我后面发出来分享!
1、v-if和v-for哪个优先级更高?
分析:
这个题目考考你的基础掌握得怎么样?其实文档里面是有详细的说明的;这也是一个很好的实践题目,项目中经常会遇到,能够看出面试者对前端的api熟悉程度和应用能力。
思路分析:
- 先给出具体的结论
- 再说为什么是这样的,说出原因(细节)
- 哪些场景可能导致我们需要这样做,面对不同的场景我们又该怎么处理
- 最后总结,根据原理举一反三
高手回答:
- 实践中不应该把v-for和v-if放一起
- 在vue2中,v-for的优先级是高于v-if,把它们放在一起,输出的渲染函数中可以看出会先执行循环再判断条件,哪怕我们只渲染列表中一小部分元素,也得在每次重渲染的时候遍历整个列表,这样会比较浪费;另外需要注意的是在vue3中则完全相反,v-if的优先级高于v-for,所以v-if执行时,它调用的变量还不存在,这样就会导致发生异常
- 通常有两种情况下导致我们这样做:
- 为了过滤列表中的项目 (比如 v-for="new in news" v-if="new.isActive")。此时定义一个计算属性 (比如 activeNews),让其返回过滤后的列表即可(比如news.filter(u=>u.isActive))。
- 为了避免渲染本应该被隐藏的列表 (比如 v-for="newin news" v-if="shouldShowNews")。此时把 v-if 移动至容器元素上 (比如 ul、ol)或者外面包一层template即可。
- 在文档中明确指出永远不要把 v-if 和 v-for 同时用在同一个元素上,显然这是一个非常重要的注意事项。
- 源码里面关于代码生成的部分,能够清晰的看到是先处理v-if还是v-for,顺序上vue2和vue3正好相反,因此产生了一些症状的不同,但是不管怎样都是不能把它们写在一起的。
2、简述 Vue 的生命周期和每个阶段做的事情
思路:
- 给出概念
- 列举生命周期各阶段
- 阐述整体流程
- 结合实践
- 扩展:vue3变化
高手回答:
1.每个Vue组件实例被创建后都会经过一系列初始化步骤,比如,它需要数据观测,模板编译,挂载实例到DOM上,以及数据变化时更新dom。这个过程中会运行叫做生命周期钩子的函数,以便用户在特定阶段有机会添加他们自己的代码。
2.Vue生命周期总共可以分为8个阶段:创建前后, 载入前后, 更新前后, 销毁前后,以及一些特殊场景的生命周期。vue3中新增了三个用于调试和服务端渲染场景。
|
生命周期v2 |
生命周期v3 |
描述 |
|
beforeCreate |
beforeCreate |
组件实例被创建之前 |
|
created |
created |
组件实例已经完全创建 |
|
beforeMount |
beforeMount |
组件挂载之前 |
|
mounted |
mounted |
组件挂载到实例上去之后 |
|
beforeUpdate |
beforeUpdate |
组件数据发生变化,更新之前 |
|
updated |
updated |
数据数据更新之后 |
|
beforeDestroy |
beforeUnmount |
组件实例销毁之前 |
|
destroyed |
unmounted |
组件实例销毁之后 |
结合实践:
beforeCreate:通常用于插件开发中执行一些初始化任务
created:组件初始化完毕,可以访问各种数据,获取接口数据等
mounted:dom已创建,可用于获取访问数据和dom元素;访问子组件等。
beforeUpdate:此时view层还未更新,可用于获取更新前各种状态
updated:完成view层的更新,更新后,所有状态已是最新
beforeunmount:实例被销毁前调用,可用于一些定时器或订阅的取消
unmounted:销毁一个实例。可清理它与其它实例的连接,解绑它的全部指令及事件监听器
可能的追问:
- setup和created谁先执行?
- setup中为什么没有beforeCreate和created?
3、Vue要做权限管理该怎么做?控制到按钮级别的权限怎么做?
分析
综合实践题目,实际开发中经常需要面临权限管理的需求,考查实际应用能力。
权限管理一般需求是两个:页面权限和按钮权限,从这两个方面论述即可。

思路
- 权限管理需求分析:页面和按钮权限
- 权限管理的实现方案:分后端方案和前端方案阐述
- 说说各自的优缺点
高手回答:
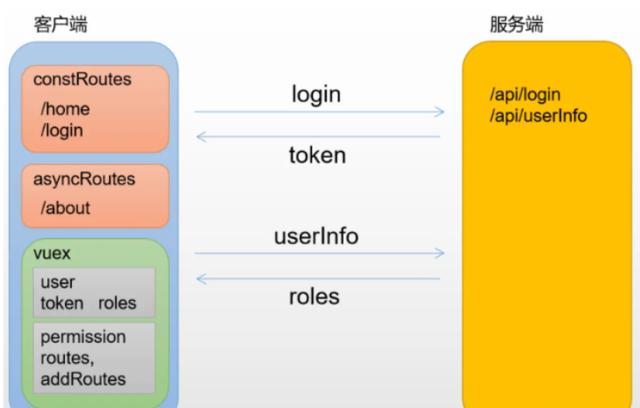
- 权限管理一般需求是页面权限和按钮权限的管理
- 具体实现的时候分后端和前端两种方案:
- 前端方案会把所有路由信息在前端配置,通过路由守卫要求用户登录,用户登录后根据角色过滤出路由表。比如我会配置一个asyncRoutes数组,需要认证的页面在其路由的meta中添加一个roles字段,等获取用户角色之后取两者的交集,若结果不为空则说明可以访问。此过滤过程结束,剩下的路由就是该用户能访问的页面,最后通过router.addRoutes(accessRoutes)方式动态添加路由即可。
- 后端方案会把所有页面路由信息存在数据库中,用户登录的时候根据其角色查询得到其能访问的所有页面路由信息返回给前端,前端再通过addRoutes动态添加路由信息
- 按钮权限的控制通常会实现一个指令,例如v-permission,将按钮要求角色通过值传给v-permission指令,在指令的moutned钩子中可以判断当前用户角色和按钮是否存在交集,有则保留按钮,无则移除按钮。
- 纯前端方案的优点是实现简单,不需要额外权限管理页面,但是维护起来问题比较大,有新的页面和角色需求就要修改前端代码重新打包部署;服务端方案就不存在这个问题,我们目前就是通过专门的角色和权限管理页面,配置页面和按钮权限信息到数据库,应用系统每次登陆时获取的都是最新的路由信息!
4、你知道 Vue scoped 原理吗?
分析:
考查你对HTML标签和CSS选择器一些知识点掌握
思路:
1.了解加了有什么用?
2.靠什么去实现这个作用的
高手回答:
Vue scoped,原理,涉及到 vue-loader 的处理策略:
一、首先呢,是 VueLoaderPlugin 策略: VueLoaderPlugin 先获取了 webpack 原来的 rules( 即 compiler.option.module.rule 的比如 test:/.vue$/ 规则),
然后创建了pitcher 规则,pitcher 中的 pitcher-loader 可以通过 resourceQuery 识别引入文件的 query 带的关键字,
进行 loader 解析;(pitcher-loader 提供了前置运行和熔断运行的机制) 然后 VueLoaderPlugin 将进行 clonedRule( 即对 vueRule 以外的 rule 进行处理),
具体是重写 resource 和 resourceQuery,使得 loader 最终能匹配上文件; 举例:对于 vue+ts 的写法,会在 vue 的 script 标签中加上 lang='ts’,
重写后 fakeresourceQuery 文件路径为 xx.vue.ts,然后结合ts-loader 的 resource 过滤方法/.tsx?$/ 匹配上文件 然后才来到:
vueRule 的 vue-loader 执行阶段;这里简单理解:VueLoaderPlugin 就是来处理 rule 的,让 loader 能够和文件匹配。处理顺序:pitcher ? clonedRule ? vueRule
二、 有了上面的匹配文件,接着来到了 vue-loader 处理环节,首先 @vue/component-compiler-utils .parse 方法可以将 .vue 文件按照 template/script/style 分成代码块,此时会根据文件路径和文件内容生成 hash 值,并赋给 id ,跟在文件参数后面;
// 形如 `id=7ba5bd90` :
// template
import {render,staticRenderFns} from "./App.vue?vue&type=template&id=7ba5bd90&scoped=true&";
// script
import script from "./App.vue?vue&type=script&lang=js&";
// style
import style0 from "./App.vue?vue&type=style&index=0&id=7ba5bd90&scoped=true&lang=css&";三、对于 style 代码块,vue-loader 会在 css-loader 前增加stylePostLoader,stylePostLoader 正是 Vue scoped 的原理核心之一,它会给每个选择器增加属性[data-v-hash] ,这里的 hash 值就是上面的 id 值;
四、同时,对于 template 的 render 块,vue-loader 的 normalizeComponent 方法,判断如果 vue 文件中有 scoped 的 style,则其返回的 options._ScopedId 为上面的 scopedId;在 vnode 渲染生成 DOM 的时候会在 dom元素上增增加 scopedId,也就是增加 data-v-hash。
这样,经过上面的过程,Vue scoped 实现了 CSS 的模块私有化。
5、谈谈你的闭包原理的理解?闭包使用场景?
分析:
- 考虑函数的嵌套
- 内部函数中引用了外不函数的变量
- 将内部函数作为返回值返回
- 参数和变量不会被垃圾回收机制回收。
主要要形成闭包的条件,闭包什么时候产生的,作用是什么(区别产生闭包和使用包)
简答:
闭包是函数和声明该函数的词法环境的组合。- MDN
在这样的词法环境下,阻止变量回收机制对变量的回收,可以访问函数内部作用域的变量。
function init() {
var name = "Mozilla"; // name 是一个被 init 创建的局部变量
function displayName() { // displayName() 是内部函数,一个闭包
alert(name); // 使用了父函数中声明的变量
}
displayName();
}
init();进一步
- 回收机制
function a(){
var i=0;
function b(){
alert(++i);
}
return b;
}
var c=a();
c();在Javascript中,如果一个对象不再被引用,那么这个对象就会被GC回收。如果两个对象互相引用,而不再被第3者所引用,那么这两个互相引用的对象也会被回收。因为函数a被b引用,b又被a外的c引用,这就是为什么函数a执行后不会被回收的原因。(来源:百科)
- 闭包优劣
优:
① 可以读取函数内部的变量
② 让这些变量的值始终保持在内存中,不会在f1调用后被自动清除。
劣:
① 使得函数中的变量都被保存在内存中,内存消耗很大,所以不能滥用闭包,否则会造成网页的性能问题。
实际遇到
let r=[]
for (let i=0;i<5;i++) {
let index=i+1
let res_all=vm.$apid.allService(100,1,index).then((val)=>{//allService(100,1,1) size,current,serviceType
let res=val.data.data.records
r[i] = res.map(item => {
return {
name: item.serviceName,
key: item.serviceId,
icon: vm.$store.state.myBaseUrl+vm.$store.state.devUrl+item.imgUrl,
cat: index
}
})
console.log(r)
})
}//循环请求异步问题
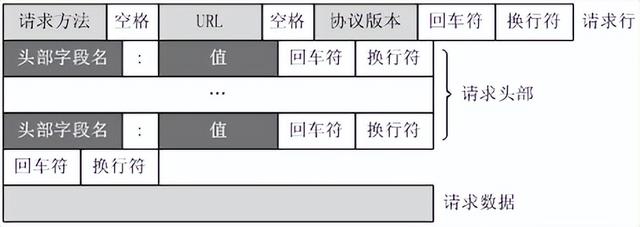
复制代码6、http请求头,请求体,cookie在哪个里面?url在哪里面?
参考菜鸟教程HTTP专栏:HTTP 教程 | 菜鸟教程
腾讯三面的时候问我http请求头都有哪些值,答不上来。。GG
服务器响应消息
HTTP响应也由四个部分组成,分别是:状态行、消息报头、空行和响应正文。
实例
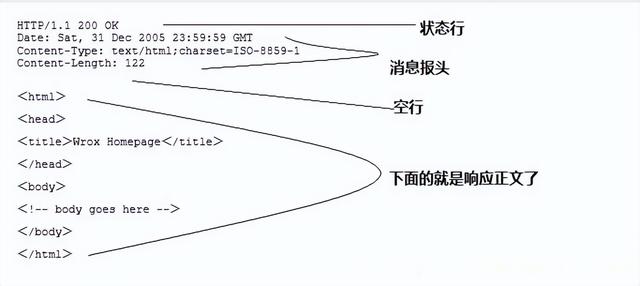
下面实例是一点典型的使用GET来传递数据的实例:
客户端请求:
GET /hello.txt HTTP/1.1
User-Agent: curl/7.16.3 libcurl/7.16.3 OpenSSL/0.9.7l zlib/1.2.3
Host: www.example.com
Accept-Language: en, mi服务端响应:
HTTP/1.1 200 OK
Date: Mon, 27 Jul 2009 12:28:53 GMT
Server: Apache
Last-Modified: Wed, 22 Jul 2009 19:15:56 GMT
ETag: "34aa387-d-1568eb00"
Accept-Ranges: bytes
Content-Length: 51
Vary: Accept-Encoding
Content-Type: text/plain输出结果:
Hello World! My payload includes a trailing CRLF.前端优化你知道哪些
分析:
性能优化是一个项目发展到一定时期之后绕不开的话题,也是每个工程师心中永远在撩拨的刺。
高手回答:
前端性能优化的工具有:Network面板、lighthouse面板、performance面板、火焰图、performance monitor面板、webpack-bundle-analyze
优化思路:
DNS查询在这里我们可以做的优化不多,DNS是我们相对不可控的一个条件,但我们仍然可以做的一个优化策略是预查询。
1、DNS预查询在文档顶部我们可以将我们即将要请求的地址的DNS预先查询,通过插入一个link标签<link rel="dns-prefetch" href="https://fonts.googleapis.com/">
来告知浏览器我们将要从这个地址(通常会是存放静态资源的CDN的地址,)拉取数据了,你先查询一下,当用到的时候就可以直接拿到对应的IP。
2、采用HTTP2:
HTTP2相对于HTTP1.1的一个主要升级是多路复用,多路复用通过更小的二进制帧构成多条数据流,交错的请求和响应可以并行传输而不被阻塞,这样就解决了HTTP1.1时复用会产生的队头阻塞的问题,同时HTTP2有首部压缩的功能,如果两个请求首部(headers)相同,那么会省去这一部分,只传输不同的首部字段,进一步减少请求的体积。
3、HTTP缓存主要分为两种,一种是强缓存,另一种是协商缓存,都通过Headers控制。
4、采用CDN
5、压缩
6、GZIP压缩
7、script加标记
8、视窗外的内容懒加载
9、减少无意义的回流
10、图片视频选择合理的尺寸:
打包Tree-shaking,消除没被引用的模块代码,减少代码体积大小,以提高页面的性能,最初由rollup提出。
11、压缩:
生产环境的代码不是给人看的,所以不需要考虑可读性(降低可读性还能提高被破解的成本o(≧口≦)o),尽可能少的字符是最优选项,webpack4+无需配置默认会压缩代码
12、使用动态import()代替静态import做条件渲染的懒加载
13、SSR
利用服务器端优先渲染出某一部分重要的内容,让其他内容懒加载,这样到达浏览器端时一部分HTML已经存在,页面上就可以呈现出一定的内容
未完待续……


如若转载,请注明出处:https://www.daxuejiayuan.com/21714.html
相关推荐
-
232交友网(2322网)
本内容来源于@什么值得买APP,观点仅代表作者本人 |作者:七大叔 大家好,我是爱音乐,爱数码,爱旅行的七大叔。上期的文章有朋友留言说希望能推荐一下2.1音箱。本期和大家聊聊关于2…
-
积分商城小程序如何推广(积分商城小程序搭建)
疫情的反复让药店线下生意几乎“停滞”,相反以“O2O”为代表的医药电商却持续火热,这里我们具体聊一下以私域为代表的O2O。私域流量的爆火让药店过去的“等人下单”转变为“精准营销,主…
-
代销货源怎么找(代销货源批发网)
养孩子是笔不小的开销,为了省钱我也找了很多方法。下面我们分析一下值不值。 首先母婴代理:入了代理,会给你一些货源群,群里询价,下单直接找群主,下单不通过上家,没有一层一层的加价。目…
-
lottie动画资源(lottie动画原理)
如果你想抓住你的网站访问者的注意力,还有什么能比动画更好呢?使用网络上免费提供的许多应用引擎,你可以很容易地让你的网站元素褪色、跳动或嗖嗖作响。在今天的文章中,我们将看到JavaS…
-
金牌网络营销(品牌营销网络)
我是一家公司的电话销售, 她的业绩一直名列前茅, 每一次季度总结和年终总结, 她都会拿到很多奖品和奖金。 最近公司来了一位新员工小迪, 正好被分到了我所在的二组。 为了让小迪在公司…
-
myexcel(myExcel读取表头)
从19年开始,企服领域突然刮起了一阵零代码的潮流,零代码产品快速进入人们的视野,这里面有老一代的表格服务器产品,有新一代的控件式设计的公有云产品,也有是蹭热度的框架类产品。 不论是…
-
股票系统下载(股票平台下载)
#炒股神器# 1.看盘工具类软件 同花顺:对于新手及普通股友来说,是一款非常不错的炒股软件,同花顺是提供行情显示、行情分析和行情交易的股票软件,也是大多数股民常用的看盘软件;pc端…
-
黑客技术联盟(黑客联盟网)
林勇 白天,他是芸芸众生中的一个小生意人,于商贾一道略有心得,悉心经营,换得一家安稳。 晚上,他是虚无黑暗中的侠客,来去无踪,踏雪无痕,唯有刻意留下印记的地方给了后来者一个信息:他…
-
技术宅社区如何获得邀请码(技术宅社区如何注册)
赛事分析: 欧塞尔VS索肖 客队: 曾经出于安全考虑禁止索肖球迷前往欧塞尔的阿贝-德尚体育场。 即使本场附加赛关键战,而本来容量应该是1000人省长在经索肖恳请后批准了600名球迷…
-
全网解析接口(全网解析下载)
市场经过前几天的深度回调,今天终于走出超跌反弹。但这不代表什么。因为市场整体板块基本上都下降了一个台阶。毫不夸张地说,从去年10月份开始进场的直至昨天,都是被套资金。我们可以简单定…