
BFS 和 DFS 实现

DAG 的拓扑排序是其节点的部分线性排序,因此如果该图有一条从 u 指向 v 的边,则 u 应该放在 v 之前的排序中。部分排序在许多情况下非常有用。调度问题,依赖解决方案。
一些有用的图表术语
- indegree – 指向它的边数。
- outdegree – 从顶点向外延伸的边数。
- Source Vertex — 没有边指向它的顶点。它的边缘只指向外面。
- Sink Vertex — 没有出边的顶点。它的边缘只指向它。
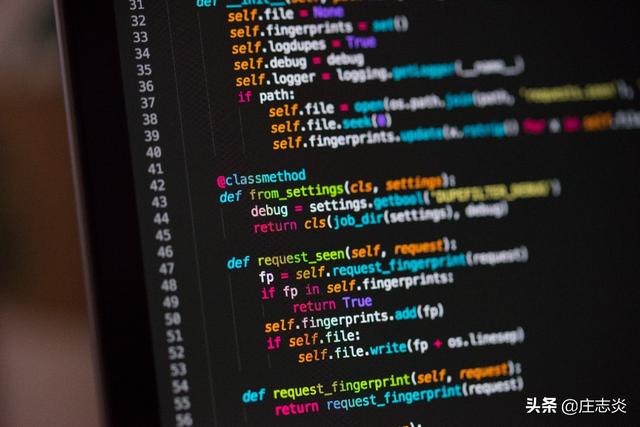
卡恩算法 (BFS)
脚步
- 将所有节点的入度存储在图中。
- 识别入度为 0 的节点。将每个节点添加到将被迭代的队列中。
- 当包含入度为 0 的节点的集合不为空时,删除一个节点。将节点存储在结果列表中。对于移除的每个节点,迭代其边缘,递减边缘上每个目标节点的入度。如果一个节点现在的入度为 0,则按照步骤 2 将其添加到队列和列表中。
- 最后,返回每个节点附加到的列表。这将包含节点的拓扑排序。
代码实现
from collections import defaultdict
class Graph:
def __init__(self, vertices):
self.graph = defaultdict(list)
self.V = vertices def add_edge(self, u, v):
self.graph[u-1].append(v-1) def topological_sort(self):
in_degree = [0]*(self.V)
visited = [0]*(self.V)
for i in self.graph:
for j in self.graph[i]:
in_degree[j] += 1
top_order = []
queue = []
from heapq import heappush, heappop
for i in range(self.V):
if in_degree[i] == 0:
heappush(queue, i) while queue:
u = heappop(queue)
if not visited[u]:
top_order.append(u+1)
for i in self.graph[u]:
in_degree[i] -= 1
if in_degree[i] == 0:
heappush(queue, i)
visited[u] = 1
return top_order## Driver code
A = 6
B = [[6, 3], [6, 1], [5, 1], [5, 2], [3, 4], [4, 2]]graph = Graph(A)
for u, v in B:
graph.add_edge(u, v)
res = graph.topological_sort()
print(res) # [5, 6, 1, 3, 4, 2]在上面的实现中,我使用了 heapq,因为我想确保结果在字典上是最小的,以防我们有多个订单。 另外,我使用了(u-1 和 v-1),因为我使用的是基于 1 的节点索引。
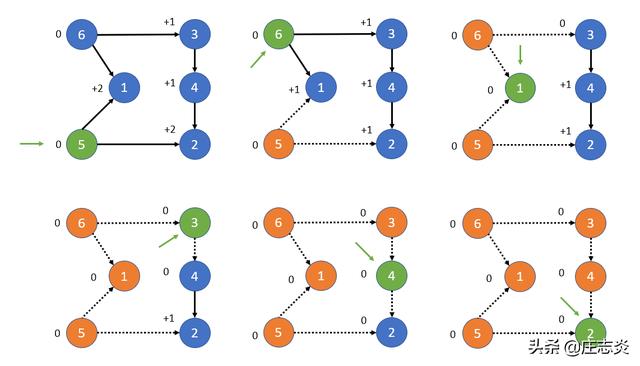
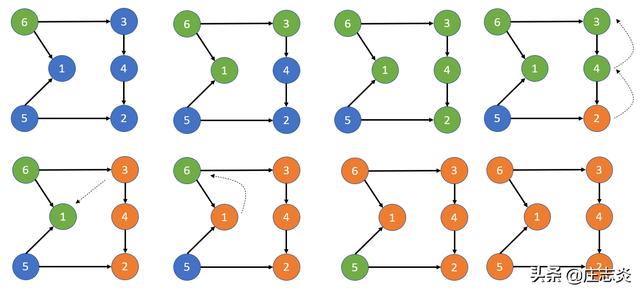
改进的深度优先搜索
脚步
- 从任何顶点开始并在其上调用 DFS 函数。
- 继续沿着该路径遍历,直到找到一个没有进一步出边的节点。
- 将其添加到拓扑排序中(我们将其插入堆栈中第 0 个索引处,否则我们将获得相反的顺序)。
- 回溯到具有更多未访问后代的前一个节点。
- 继续,直到您访问了所有节点。
代码实现
from collections import defaultdict
class Graph:
def __init__(self, vertices):
self.graph = defaultdict(list)
self.V = vertices
def add_edge(self, u, v):
self.graph[u-1].append(v-1) def helper(self,u,visited, res):
visited[u] = True
for i in self.graph[u]:
if visited[i] == False:
self.helper(i, visited, res)
res.insert(0, u+1) def topological_sort(self):
visited = [False]*self.V
res =[]
for i in reversed(range(self.V)):
if visited[i] == False:
self.helper(i, visited, res)
return res## Driver code
A = 6
B = [[6, 3], [6, 1], [5, 1], [5, 2], [3, 4], [4, 2]]
graph = Graph(A)
for u, v in B:
graph.add_edge(u, v)
res = graph.topological_sort()
print(res) # [5, 6, 1, 3, 4, 2]在上面的实现中,我使用了 reversed(range(self.V)) ,因为我想确保结果在字典上是最小的,以防我们有多个订单。
快乐编码!
关注七爪网,获取更多APP/小程序/网站源码资源!


如若转载,请注明出处:https://www.daxuejiayuan.com/38808.html
相关推荐
-
小明永久看看(明世隐重做成功,胜率飙升,如何克制明世隐加呆射的体系呢?)
大家好我是指尖,S28赛季涌现出了好多非主流的玩法,或许这才叫百花齐放的版本吧,射手中有传统的暴击流,也有了一个法球流,暗信放弃了惩击玩起了弱化和 晕眩,明世隐走上单打出了线霸级的…
-
问仙网页游戏下载(问仙网页游戏官网)
第三章 棺裂 言无讳年少气盛,而且又不懂得各种忌讳事项,一时愤慨之下,便情不自禁地冲了出来。此时,见言当归一脸肃穆,心中也有些不安。不过,他还是想听言当归详细解释一下,故而,双手依…
-
哔哩哔哩无水印视频下载(最右无水印视频下载)
对于一个头条“玩家”,经常看到别人发布的影视剪辑作品,播放量很高,羡慕之余,自己也想尝试一把,也想通过视频赚点“外快”。把该有的剪辑技能都学会了,最后发现想剪辑的视频资源(尤其是v…
-
谷谷粉搜索,(谷粉搜索谷歌搜索)
新生代父母对营养、健康、安全、优质的婴幼儿辅食倍加青睐。香港的一群营养师善用专业知识,创立了专为婴幼儿而设的即食「辅食品」品牌—「宝宝百味」,标榜低糖、低钠、高纤及无添加,广受新手…
-
自己开美甲店赚钱吗怎么样,(自己开美甲店赚钱吗现在)
为什么普通人做生意赚不到钱? 因为时刻想着有人带带自己,有人带着自己发财。 如果你做生意就是别人说了什么 ,你就去做什么或者就是去投资,那你是赚不到钱的。也许你还会亏很多的钱。比如…
-
免费o2o 源码下载(o2o 下载)
编辑导语:常规做法会在购物车环节设置数量阈值,库存小于阈值显示用户库存紧张。然后在下单环节完成扣减库存的情况。如果是秒杀或者是类似唯品会的抢购模式,则可以在购物车扣减库存,增加倒计…
-
精彩悬疑短片小说——正义的叹息(第三节)
第三节 最大的嫌疑人 三天之后,紧张且缜密的调查初步结束,吴大队长继续召集成员们开会,死者的仇家几乎都有不在场证据: 木工老刘家带着那个不成器的大龄儿子去相亲,相亲对象全家都能作证…
-
bowpad官网owpad(bowpad官网)
KOL,关键意见领袖(Key Opinion Leader)。通常被认为是:拥有更多、更准确的产品信息,且为相关群体所接受或信任,并对该群体的购买行为有较大影响力的人。 简单来说,…
-
非主流系统小说txt百度云(《非主流系统》)
本文给读者推荐一本有趣的小说《我快亏成麻瓜了》,这本小说应该算是文娱类小说,情节发展却跟一般的文娱类小说略有差异。 主角林冬是地球上的一个90后,在书中出场时的身份是北电表演系的学…
-
罗布奥特曼免费影视(戴拿奥特曼飞飞影视)
当腾讯热衷于“山寨”时,网易在自研游戏;当国内大多数游戏厂商都在“山寨”时,网易选择了随大流。现如今网易成了国内最大的“换皮”游戏厂商,究竟是什么原因,让一个把自研当作骄傲的游戏公…