
arXiv论文“TridentNetV2: Lightweight Graphical Global Plan Representations for Dynamic Trajectory Generation“,上传于2022年3月,作者来自UC San Diego。


该文提出一个用于自主导航的动态轨迹生成框架,该框架不依赖HD地图作为底层表示。HD地图已成为大多数自动驾驶框架的关键组成部分,其中包括完整的道路网络信息,并在厘米级进行标注,包括可遍历的航路点、车道信息和交通信号。不同的是,在给定一个基于有名无实图(nominal graph)的全局规划和一个轻量级场景表示的情况下,该方法实时模拟可行自车为中心轨迹的分布。通过嵌入背景信息,如人行横道、停车标志和交通信号,这个方法在多个城市导航数据集(包括各种交叉口机动)中做到了低错误,同时保持了实时性能并降低了网络复杂性。
该文是作者之前工作“Tridentnet: A conditional generative model for dynamic trajectory generation“扩展:

作者之前引入一种轻量级地图表征的方法,显式地实施几何约束,并使用条件生成模型学习可行的轨迹。另外还给了一个新数据集 NominalScenes 1.0,用于定量验证提出的模型。如图是TridentNet 的表征, 包括 OpenStreetMaps(OSM), 局部语义地图 和一个 Conditional Variational Autoencoder (CVAE)生成轨迹。
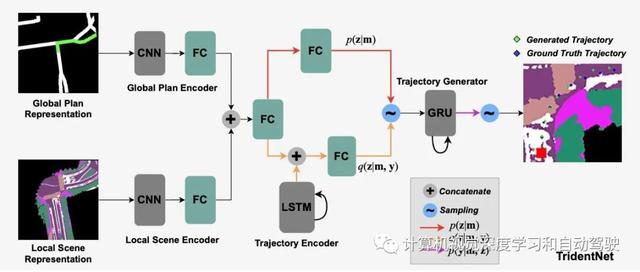
下图是本文作者提出的TridentNetV2 模型概览:这种方法使用全局规划和自动生成语义图而定义;全局规划以一个图mg表示,该图定义了道路连通性以及在给定GPS姿势或起点的情况下到达特定目的地所需的高级指令;该全局规划表征为轨迹生成模块的粗方向提示;另一方面,局部语义表示ms,描述了附近的特征,如可行驶区域、车道标记和人行道;每次接收到新自车姿势更新时,作为定位过程的一部分,mg和ms两种表征都会更新。
在每次更新期间应用CVAE方法来模拟潜轨迹p(y | m)分布,在给定全局规划和语义场景表示的情况下,该潜轨迹p(y | m)可由自车执行;其中,y={(xi,yi)}是通过地平线动态生成的轨迹,m={mg,ms}是mg和ms的联合嵌入;这些特征可以共同提供详细的语义,对场景和全局规划的信息进行编码,其帮助网络了解道路要素之间的关系。
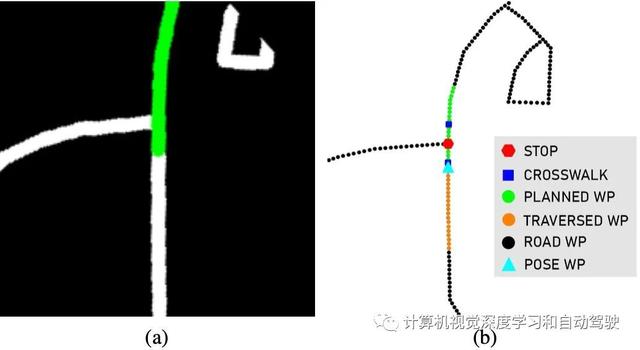
为了解释点对点导航,并确定在交叉口是否需要左转或右转,需要一个全局规划。OpenStreetMaps生成的光栅化表示可以用来编码高级信息。基于图像的全局规划,通过GPS估计粗略姿势、IMU估计航向(偏航)和里程计数据,更新GPS测量之间的粗略车辆状态,对到特定点所需的规划编码。为了防止偏向特定方向或机动类型,利用航向执行2D旋转,在自车框架中表征该全局规划。
如图是OSM做有名无实表征:(a)光栅化表示和(b)图表示 。
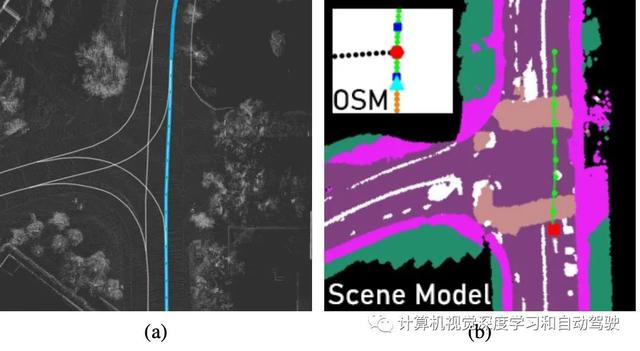
尽管OSM的全局规划方法可以对目的地的高级指令进行编码,但这些指令的准确性较低,并且不能提供有关车道标注和可驾驶区域的额外信息,而精确的路径跟踪和导航需要这种信息。为了结合这些上下文信息,轨迹的生成模型以局部语义场景表征为条件。
如图是自主导航的全局规划和场景表示说明:(a)使用高清地图生成的轨迹(蓝色轨迹表示规划/灰色轨迹表示完整的道路网络),(b)无高清地图情况下,基于有名无实的OSM全局规划和自动生成的语义场景表征,动态生成的轨迹(显示为绿色轨迹)。
首先,通过沿感兴趣的区域驾驶一次自动生成2D语义地图,并做必要的后处理;地图由因子 D 做离散化,并由一幅图像表示,该图像对可行驶区域、人行道、人行横道、车道标线和植被的信息进行编码。最后,考虑到上下文信息仅对有限范围内的导航必要,利用定位执行以自车为中心的坐标转换,在运行时执行L×L区域裁剪过程。然后,将这种局部语义场景表示用作模型的输入。
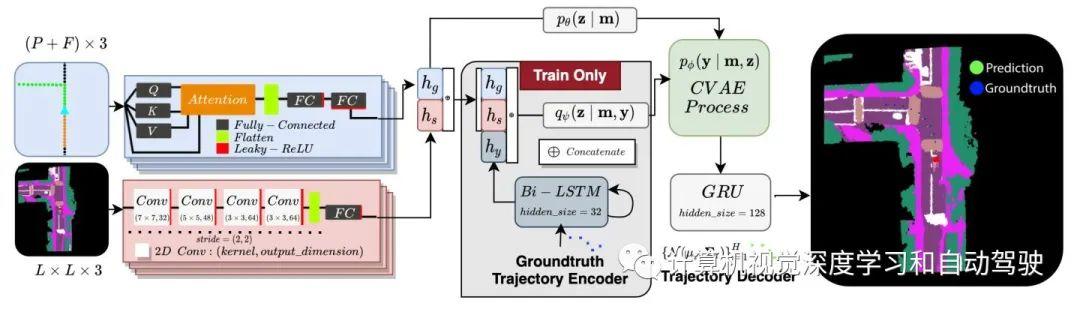
这种方法的一个优点是,它通过利用摄像头-激光雷达的投影几何技术来考虑具有陡坡和弯曲道路的路段。基于CVAEs的多模态特征,把其目标函数扩展去做城市驾驶场景的动态轨迹生成。该方法用图表示对全局规划进行编码。此外,引入均方误差(MSE)损失项,可以降低相对真值轨迹的误差。因此,如下为最小化的总目标函数,其中y?对应于预测的轨迹
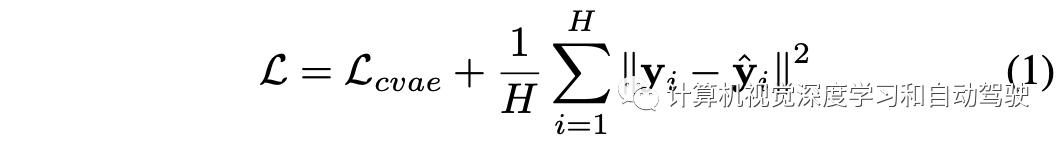
为了解释各种道路要素之间的关系以及全局规划中的穿过/规划轨迹,在全局规划编码器中应用了自注意机制。注意操作如下定义,其中C=3,而Q、K和V是mg的线性投影,分别称为查询、键和值。
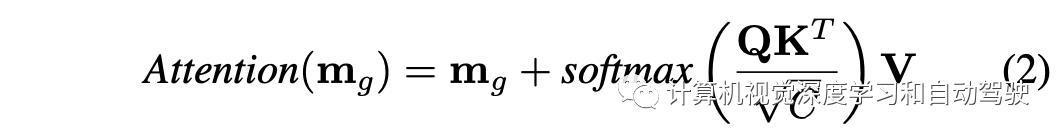
然后将多层感知(MLP)做输出的矢量化表征;得到一项全局规划hg。这个语义场景编码器生成一个语义模型的压缩表征hs。
实验提供的GT轨迹会用定位做自动注释。为了防止速度偏差,每个轨迹在训练前做内插,并延伸到30m的地平线,其特征是H=10个航路点,间距为3m。作为参考,全球规划编码信息的精度范围约为1m。另一方面,语义图框中标注的轨迹标注在2cm范围。
实验导航操作包括车道跟踪、三向和四向交叉口、U形转弯和急转弯。使用粗略的GPS估计,根据与自车最接近的匹配OSM航路点生成图信息,根据航路点的方向去旋转附近节点位置。在不依赖IMU的情况下提供OSM航路点近似值。
实验数据集NominalScenes 1.0由6128个训练样本和2864个测试样本组成,每个样本都由一个全局规划、一个局部语义场景表示、一个GT轨迹、IMU数据、一个Unix Epoch 时间戳、语义地图框架中自车的状态(精度在2cm以内)以及全局坐标系的状态(纬度和经度精度在1米以内)等组成。
其次,一个名为IntersectionScenes 1.0的新数据集在这项工作中引入,重点是评估三向和四向交叉口导航的性能。该数据集由2924个训练样本和1506个插值后的测试样本组成。
对于这两个数据集,全局规划由基于GPS的规划器生成,该规划器采用Dijkstra 最短路径搜索算法,并为光栅和图形模型分别生成表征。图形表征版包括OSM提供的停车标志、交通信号和人行横道。为了方便起见,保留了OSM中的纬度和经度信息,支持将来规划器的实现。
实验结果如下:




如若转载,请注明出处:https://www.daxuejiayuan.com/32600.html
相关推荐
-
js在线编辑器(网页python在线编辑器)
伴随着5G时代的到来,web3D交互展示技术发展的如火如荼。我们总能在网页上看到动态可交互的模型、展厅。人们看得过瘾,但却不知道它们制作的过程是很复杂的。它需要建模师进行建模渲染,…
-
中国老黄历下载(中国老黄历每日宜忌)
六爻时位图 一个卦,共六个爻。分别是初,二,三,四,五,上。它代表着宇宙万物,时位的变动演绎出宇宙人生的变化之道。 易经卦象的六个爻,分别代表六个时位。从空间来讲,第一爻,位置最低…
-
商务网站接受网上支付的软件工具是(商务网站用什么跟踪用户的网上活动)
电子商务成功的公式在很大程度上取决于通过优化客户体验来提高客户满意度。首先是建立一个可靠的技术和服务堆栈,使您能够监控和评估业务的各个方面,使您能够立即进行调整并纠正路线以获得最佳…
-
电驴资源用什么下载_(电驴资源下载软件)
作者很任性,没空不更新。今天有空,给大家说说关于下载的事。本人是80后,一直都喜欢在网上下载资源,从bt,磁力,电驴什么的。某下载软件之前也是免费的,然后………
-
金排题库系统(考易题库系统)
随着时代的发展,我国在党的领导下发展得愈发强盛,学习了解党史也就成了我们每个人所应该做的事情。那么我们应该如何学习党史呢,接下来柒点云就介绍一款学习党史答题的系统。 党支部功能,党…
-
快点阅读下载(阅读下载的小说在哪个文件夹)
PS:带下划线文字为链接 本文作者:大白 公众号:大白推书 阅读相信很多书友在用,一款很好用的网络小说阅读器,也是一款漫画阅读器,同时还是一个导航软件,600+的RSS基本满足你的…
-
软件下载网站推荐(软件下载网站排行榜)
手机上除了每天常用的那几个软件外,你还知道有哪些好用的App吗?下面这10个相见恨晚的宝藏App,知乎20W人热推,后悔没早点知道。 01 微商视频助手 如果你从事的是微商、自媒体…
-
导航网站大全(常用网址导航大全)
装修旺季的到来,很多业主都想找装修公司装修房子,大部分人没有太多时间在线下一家家考察,都选择在网上挑选合适的然后再面谈。 按照排名考察有一定的参考性,面对众多的装修平台你要这样挑选…
-
库娱网(求娱乐平台)
陈若轩也会参演angelababy、张翰主演的新剧《生活在别处的我》 靳东、宋佳主演的《纵有疾风起》4月29日起东方卫视、北京卫视、腾讯视频播出 谷爱凌中国人民保险代言,广告已拍 …