
△ 一、先看看效果:
完整版
△ 二、点评:
1 这是一个完整版的教程,从图片处理、文字识别、数据保存和相关软件安装,比较完整,适合练手、学习。
2 文字中“男女”识别不出来,可能与我的调试没有到位,或者原图表格中的文字是粗体有关。
3 虽然有小bug,但是讲解清楚,注释详细,文章较长,适合收藏,慢慢学习。
△ 三、内容:
1 代码分步讲解,图文并茂。
2 完整代码(精简版)。
3 pytesseract软件安装,因为这个软件安装比较特殊,有时候可能会有一些麻烦,故我特别放在此处交代一下。
△ 四、代码分步讲解:
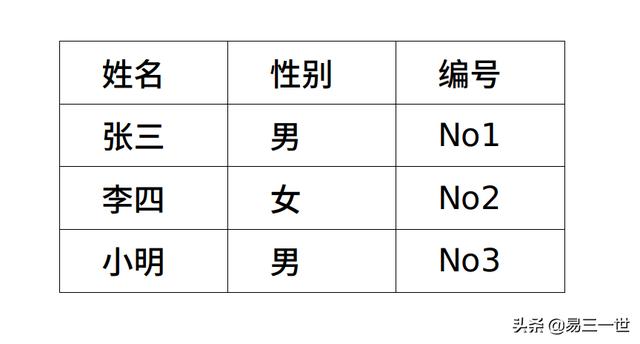
1 原图:abc.png
示范
2 第一步:导入模块
import re
import cv2
import numpy as np
import pytesseract3 第二步:图片处理
# 2-1 读取识别图片的表格原图
src='/home/xgj/Desktop/png-table-word/120/img/abc.png'
raw = cv2.imread(src, 1)# 2-2 初步处理
# 灰度图片
gray = cv2.cvtColor(raw, cv2.COLOR_BGR2GRAY)
# 二值化
binary = cv2.adaptiveThreshold(~gray, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 35, -5)
#cv2.imshow("1", binary) #展示图片
#cv2.waitKey(0)横线识别,很重要,scale = 18需要自己调节。
rows,cols=binary.shape
# 需要自己调节-1
scale = 18 # 越大越容易识别文字横线,引起误差,22误差就大。
#识别横线
kernel = cv2.getStructuringElement(cv2.MORPH_RECT,(cols//scale,1))
eroded = cv2.erode(binary,kernel,iterations = 1)
#cv2.imshow("2",eroded)
dilatedcol = cv2.dilate(eroded,kernel,iterations = 10)
#cv2.imshow("3",dilatedcol)
#cv2.waitKey(0)
竖线识别,也是一样的。
# 2-4 识别竖线
# 需要自己调节-2
scale = 10 # 调成10,如果20太敏感了
kernel = cv2.getStructuringElement(cv2.MORPH_RECT,(1,rows//scale))
eroded = cv2.erode(binary,kernel,iterations = 1)
dilatedrow = cv2.dilate(eroded,kernel,iterations = 10)
#cv2.imshow("4",dilatedrow)
#cv2.waitKey(0)
交点显示,很重要,容易遗漏。
# 2-5 标识交点,关键处,后面需要提取,用来截取小单元格
bitwiseAnd = cv2.bitwise_and(dilatedcol,dilatedrow)
cv2.imshow("5",bitwiseAnd)
cv2.waitKey(0)
不清楚,自己操作后就知道了,还可以
# 2-6 标识表格
merge = cv2.add(dilatedcol,dilatedrow)
cv2.imshow("6",merge)
cv2.waitKey(0)
# 查看效果,用于提取后的文字识别,很重要
# 2-7 两张图片进行减法运算,去掉表格框线
merge2 = cv2.subtract(binary,merge)
cv2.imshow("7",merge2)
cv2.waitKey(0)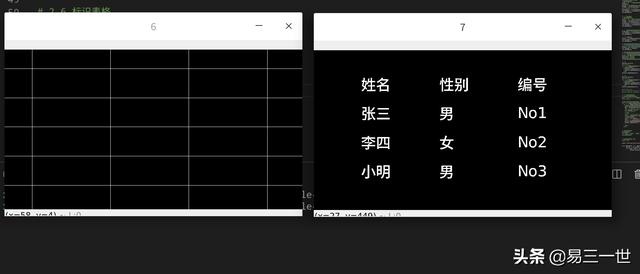
第三步:获取左上角的交点,并截取每一个小单元格
# 3-1 识别黑白图中的白色交叉点,将横纵坐标取出
ys,xs = np.where(bitwiseAnd>0)
mylisty=[] #纵坐标
mylistx=[] #横坐标
#通过排序,获取跳变的x和y的值,说明是交点
i = 0
myxs=np.sort(xs)
#print(myxs)
for i in range(len(myxs)-1):
# 需要自己调节-3
if(myxs[i+1]-myxs[i]>5): # 自定义:5
mylistx.append(myxs[i])
i=i+1
mylistx.append(myxs[i])
i = 0
myys=np.sort(ys)
#print(myys)
for i in range(len(myys)-1):
# 需要自己调节-3
if(myys[i+1]-myys[i]>5): #5
mylisty.append(myys[i])
i=i+1
mylisty.append(myys[i])
#print(mylisty)
#print('mylisty',mylisty)
#print('mylistx',mylistx)
# 3-2 截取小单元格
# 定义一个空格数据列表
data = [[] for i in range(len(mylisty)-1)]
#print(data)
#循环y坐标,x坐标分割表格
for i in range(len(mylisty)-1):
for j in range(len(mylistx)-1):
#在分割时,第一个参数为y坐标,第二个参数为x坐标
ROI = merge2[mylisty[i]:mylisty[i+1],mylistx[j]:mylistx[j+1]]
#ROI = raw[mylisty[i]:mylisty[i+1],mylistx[j]:mylistx[j+1]] # 原图识别率不高
cv2.imshow("sub_pic" + str(i) + str(j), ROI)
#cv2.waitKey(0)
# 识别
#text1 = pytesseract.image_to_string(ROI) #读取文字,此为默认英文
text1 = pytesseract.image_to_string(ROI, lang='chi_sim+eng') #读取文字,此为默认英文
# 去除特殊字符
text1 = re.findall(r'[^\*"/:?\\|<>″′‖〈\n]', text1, re.S)
text1 = "".join(text1)
print('单元格图?信息:' + text1)
data[i].append(text1)
j=j+1
i=i+1
# 查看识别效果
print(data)
#[['姓名', '性别', '编号'], ['张三', '', 'N01'], ['李四', '', 'N02'], ['小明', '', 'No3']]
cv2.waitKey(0)第四步:存入文件中
# 第四步:存入csv中
import csv
path='/home/xgj/Desktop/png-table-word/120/data.csv'
with open(path, "w", newline='') as csv_file:
writer = csv.writer(csv_file, dialect='excel')
for index, item in enumerate(data):
writer.writerows([[item[0], item[1], item[2]]]) # 有三列,可以自己根据原表格定义△ 五、完整代码:精简版
# -*- coding: utf-8 -*-
# 第一步:导入模块
import re
import cv2
import csv
import numpy as np
import pytesseract
# 第二步:图片处理
# 2-1 读取识别图片的表格原图
src='/home/xgj/Desktop/png-table-word/120/img/abc.png'
raw = cv2.imread(src, 1)
# 2-2 初步处理
# 灰度图片
gray = cv2.cvtColor(raw, cv2.COLOR_BGR2GRAY)
# 二值化
binary = cv2.adaptiveThreshold(~gray, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 35, -5)
# 2-3 识别横线
rows,cols=binary.shape
scale = 18 # 越大越容易识别文字横线,引起误差,22误差就大。
#识别横线
kernel = cv2.getStructuringElement(cv2.MORPH_RECT,(cols//scale,1))
eroded = cv2.erode(binary,kernel,iterations = 1)
dilatedcol = cv2.dilate(eroded,kernel,iterations = 10)
# 2-4 识别竖线
scale = 10 # 调成10,如果20太敏感了
kernel = cv2.getStructuringElement(cv2.MORPH_RECT,(1,rows//scale))
eroded = cv2.erode(binary,kernel,iterations = 1)
dilatedrow = cv2.dilate(eroded,kernel,iterations = 10)
# 2-5 标识交点,关键处,后面需要提取,用来截取小单元格
bitwiseAnd = cv2.bitwise_and(dilatedcol,dilatedrow)
cv2.imshow("5",bitwiseAnd)
cv2.waitKey(0)
# 2-6 标识表格
merge = cv2.add(dilatedcol,dilatedrow)
cv2.imshow("6",merge)
cv2.waitKey(0)
# 查看效果,用于提取后的文字识别,很重要
# 2-7 两张图片进行减法运算,去掉表格框线
merge2 = cv2.subtract(binary,merge)
cv2.imshow("7",merge2)
cv2.waitKey(0)
# 第三步:获取左上角的交点,并截取每一个小单元格
# 3-1 识别黑白图中的白色交叉点,将横纵坐标取出
ys,xs = np.where(bitwiseAnd>0)
mylisty=[] #纵坐标
mylistx=[] #横坐标
i = 0
myxs=np.sort(xs)
for i in range(len(myxs)-1):
if(myxs[i+1]-myxs[i]>5): # 自定义:5
mylistx.append(myxs[i])
i=i+1
mylistx.append(myxs[i])
i = 0
myys=np.sort(ys)
for i in range(len(myys)-1):
if(myys[i+1]-myys[i]>5): #5
mylisty.append(myys[i])
i=i+1
mylisty.append(myys[i])
# 3-2 截取小单元格
# 定义一个空格数据列表
data = [[] for i in range(len(mylisty)-1)]
#循环y坐标,x坐标分割表格
for i in range(len(mylisty)-1):
for j in range(len(mylistx)-1):
#在分割时,第一个参数为y坐标,第二个参数为x坐标
ROI = merge2[mylisty[i]:mylisty[i+1],mylistx[j]:mylistx[j+1]]
cv2.imshow("sub_pic" + str(i) + str(j), ROI)
# 识别
text1 = pytesseract.image_to_string(ROI, lang='chi_sim+eng') #读取文字,此为默认英文
# 去除特殊字符
text1 = re.findall(r'[^\*"/:?\\|<>″′‖〈\n]', text1, re.S)
text1 = "".join(text1)
print('单元格图?信息:' + text1)
data[i].append(text1)
j=j+1
i=i+1
cv2.waitKey(0)
# 第四步:存入csv中
# 自定义存入文件地址和文件名
path='/home/xgj/Desktop/png-table-word/120/data.csv'
# 写入
with open(path, "w", newline='') as csv_file:
writer = csv.writer(csv_file, dialect='excel')
for index, item in enumerate(data):
writer.writerows([[item[0], item[1], item[2]]]) # 有三列,可以自己根据原表格定义△ 六、pytesseract安装:
1、先安装tesseract-ocr:
sudo apt-get install tesseract-ocr # 本机是deepin-linux操作系统2、测试:
tesseract -v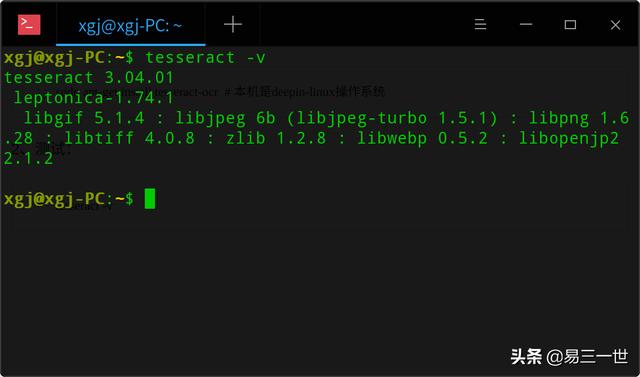
3、安装pytesseract:
sudo pip3.8 install pytesseract # 本机是python3.84、查看语言包tesseract:
tesseract --list-langs初始安装,查看效果如下:
tesseract –list-langs
osd
eng
equ
Note: These two data files are compatible with older versions of Tesseract.
osd is compatible with version 3.01 and up,
and equ is compatible with version 3.02 and up.
没有安装中文简体包。
5、安装中文简体包:
https://github.com/tesseract-ocr/tessdata # 下载地址下载,解压,本机是将chi_sim.traineddata复制到下面文件夹下,注意sudo
/usr/share/tesseract-ocr/tessdata
在查看。
简体中文安装成功
△ 小结:
自己实测和操作过,细节也注释了。
赋诗一首,更显原创。
===========
缝隙爱好学习,
实测代码详细,
图文并茂有心,
快乐分享搭梯。
===========



如若转载,请注明出处:https://www.daxuejiayuan.com/23798.html
相关推荐
-
ps免费中文版免激活(ps免费中文版安装包)
在后台有很多小可爱会问小编,有没有PS的软件?确实,我发现越来越多的同学意识到掌握PS的重要性,我说的是Photoshop,而不是手机P图类软件哦~ PS不仅是大学生的面试薪资加分…
-
淘客网站模板(淘宝客网站模板)
小淘客如何选款,一直是大家非常关心的问题。 特别是对于新入行的淘宝客新手来说,选款一直是比较头痛的问题。只见别人群里都是好单子,自己怎么就发现不了那些好单子呢? 自己选出的单子要不…
-
飞蛙崖瀑布(飞蛙影视TV是免费的吗)
亚马孙热带雨林以神秘险恶闻名于世,很多地方至今还没有人类踏足,热带雨林看似是人间天堂,实则是人类的生命禁区。 雨林深处由于终年不见天日,气候炎热潮湿,植物腐烂滋生的瘴气不是人类所能…
-
dzzit中文怎么读(dzzit怎么读)
自从被好友安利了背包十年,就想住完所有的店,可惜只住了几个。总在期待下一次的旅行目的地,希望那座城有背包。 去拥抱陌生,去期待惊喜。 住青旅并不丢脸,读书时没钱很正常,工作后省点有…
-
在线md5加密解密(在线md5加密解密工具)
Go 的随机数生成器是生成难以猜测的密码的好方法。 你可以使用 Go 编程语言提供的随机数生成器来生成由 ASCII 字符组成的难以猜测的密码。尽管本文中提供的代码很容易阅读,但是…
-
vue论坛系统(论坛系统答辩问题)
论坛一词,大家都比较熟悉了。通过论坛,我们可以非常方便地查阅所需的主题消息,并且可以做到很好的互动交流。目前,大家在使用的论坛基本上是公域的、人人都能参与的论坛平台,如果涉及内部比…
-
云播放网页版(打开网页云播放)
来源:人民网 原创稿 编者按:不用预约、不用排队,重要文物、精品展览“云上”看;智慧文博、多元服务,文艺出游体验更丰富。“五一”假期,线上关注精品展览,“云”游重点文博展馆。足不出…
-
yy导航(yyfuli导航)
随着国内的经济崛起,交通越来越发达,导航软件也成了生活中必备的软件。出去旅游的时候,接触一个新地方的时候,点开软件,都是那么熟练的操作。然而自从Google退出国内之后,高德地图、…
-
开放源代码软件(开放源代码的网络操作系统是)
也许每个人都或多或少地存在这样或那样的小秘密:有的我们不愿意对别人说,有的我们乐意和最亲近的人说。 这些秘密虽属于我们和朋友们,却常常不能激起多大的波澜。因此,我们通常会将它藏起来…
-
在线下单平台(捷配pcb在线下单)
为切实做好疫情防控期间居民生活需求保障,进一步加强社区生活物资保障末端供应,按照长春市商务局提出的“尽量减少外出购物,尽量选择线上购物”的倡议要求,宽城区商务局重点梳理了一批“线上…
