
造轮子内存池原因引入
作为C/C++程序员, 相较java程序员的一个重大特征是我们可以直接访问内存, 自己管理内存, 这个可以说是我们的特色, 也是我们的苦楚了.
java可以有虚拟机帮助管理内存, 但是我们只能自己管理内存, 一不小心产生了内存泄漏问题, 又特别是服务器的内存泄漏问题, 进程不死去, 泄漏的内存就一直无法回收.
所以对于内存的管理一直是我们C系列程序员深挖的事情.
所以对于C++有智能指针这个东西. 还有内存池组件. 内存池组件也不能完全避免内存泄漏, 但是它可以很好的帮助我们定位内存泄漏的点, 以及可以减少内存申请和释放的次数, 提高效率
大量的malloc/free小内存所带来的弊端
弊端
- malloc/free的底层是调用系统调用, 这两者库函数是对于系统调用的封装, 频繁的系统调用所带来的用户内核态切换花费大量时间, 大大降低系统执行效率
- 频繁的申请小内存, 带来的大量内存碎片, 内存使用率低下且导致无法申请大块的内存
- 没有内存回收机制, 很容易造成内存泄漏
内存碎片出现原因解释
- 内部内存碎片定义: 已经被分配出去了(明确分配到一个进程), 但是无法被利用的空间
- 内存分配的起始地址 一定要是 4, 8, 16整除地址
- 内存是按照页进行分配的, 中间会产生外部内存碎片, 无法分配给进程
- 内部内存碎片:频繁的申请小块内存导致了内存不连续性,中间的小内存间隙又不足以满足我们的内存申请要求, 无法申请出去利用起来, 这个就是内部内存碎片.
出现场景
最为典型的场景就是高并发是的频繁内存申请, 释放. (http请求) (tcp连接)
大牛解决措施(Nginx内存池)
nginx内存池, 公认的设计方式非常巧妙的一款内存池设计组件, 专门针对高并发下面的大量的内存申请释放而产生的.
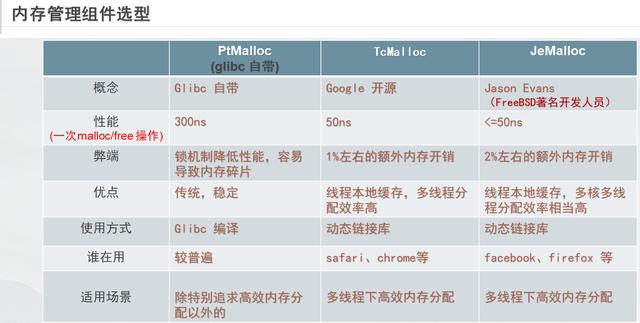
在系统层,我们可以使用高性能内存管理组件 Tcmalloc Jemalloc(优化效率和碎片问题)
在应用层: 我们可以根据需求设计内存池进行管理 (高并发可以借助nginx内存池设计)
内存池技术
啥叫作内存池技术
就是说在真正使用内存之前, 先提前申请分配一定数量的、大小相等(一般情况下)的内存块留作备用, 当需要分配内存的时候, 直接从内存块中获取. 如果内存块不够了, 再申请新的内存块.
内存池: 就是将这些提前申请的内存块组织管理起来的数据结构
优势何在:统一对程序所使用的内存进行统一的分配和回收, 提前申请的块, 然后将块中的内存合理的分配出去, 极大的减少了系统调用的次数. 提高了内存利用率. 统一的内存分配回收使得内存泄漏出现的概率大大降低
内存池技术为啥可以解决上文弊端
高并发时系统调用频繁(malloc free频繁),降低了系统的执行效率
- 内存池提前预先分配大块内存,统一释放,极大的减少了malloc 和 free 等函数的调用。
频繁使用时增加了系统内存的碎片,降低内存使用效率
- 内存池每次请求分配大小适度的内存块,最大避免了碎片的产生
没有内存回收机制,容易造成内存泄漏
- 在生命周期结束后统一释放内存,极大的避免了内存泄露的发生
高并发内存池nginx内存池源码刨析
啥是高并发
系统能够同时并行处理很多请求就是高并发
高并发具备的特征
- 响应时间短
- 支持并发用户数高
- 支持用户接入量高
- 连接建立时间短
nginx_memory_pool为啥就适合高并发
内存池生存时间应该尽可能短,与请求或者连接具有相同的周期
减少碎片堆积和内存泄漏
避免不同请求连接之间互相影响
一个连接或者一个请求就创建一个内存池专门为其服务, 内存池的生命周期和连接的生命周期保持一致.
相关视频推荐
学习地址:C/C++Linux服务器开发/后台架构师【零声教育】-学习视频教程-腾讯课堂
需要C/C++ Linux服务器架构师学习资料加qun812855908获取(资料包括C/C++,Linux,golang技术,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK,ffmpeg等),免费分享
仿写nginx内存池
实现思路
- 对于每个请求或者连接都会建立相应的内存池,建立好内存池之后,我们可以直接从内存池中申请所需要的内存,不用去管内存的释放,当内存池使用完成之后一次性销毁内存池。
- 区分大小内存块的申请和释放,大于内存池块最大尺寸的定义为大内存块,使用单独的大内存块链表保存,即时分配和释放
- 小于等于池尺寸的定义为小内存块,直接从预先分配的内存块中提取,不够就扩充池中的内存,在生命周期内对小块内存不做释放,直到最后统一销毁。
内存池大小, 以及内存对齐的宏定义

#define MP_ALIGNMENT 32#define MP_PAGE_SIZE 4096#define MP_MAX_ALLOC_FROM_POOL (MP_PAGE_SIZE-1) #define mp_align_ptr(p, alignment) (void *)((((size_t)p)+(alignment-1)) & ~(alignment-1))//分配内存起点对齐结构定义以及图解分析
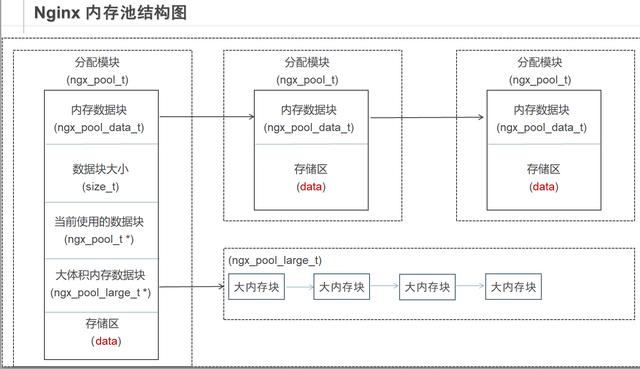
typedef struct mp_large_s { struct mp_large_s* next; void* alloc;//data区} mp_large_s; typedef struct mp_node_s { unsigned char* last;//下一次内存分配的起点 unsigned char* end;//当前内存块末尾 size_t failed;//当前内存块分配失败的次数 struct mp_node_s* next;} mp_node_s; typedef struct mp_pool_s { mp_large_s* large;//指向大块内存起点 mp_node_s* current;//指向当前可分配的小内存块起点 int max;//小块最大内存 mp_node_s head[0];//存储地址, 不占据内存,变长结构体技巧 //存储首块小内存块head地址} mp_pool_s;- large 指向第一个大块
- current 指向当前可分配的小块
- head 始终指向第一块小块
mp_node_s 小块内存结构
- last 下一次内存分配的起点, 本次内存分配的终点
- end 块内存末尾
- failed 当前内存块申请内存的失败次数, nginx采取的方式是失败次数达到一定程度就更换current,current是开始尝试分配的内存块, 也就是说失败达到一定次数, 就不再申请这个内存块了.
mp_large_s 大块内存块
- 正常的申请, 然后使用链表连接管理起来.
- alloc 内存块, 分配内存块
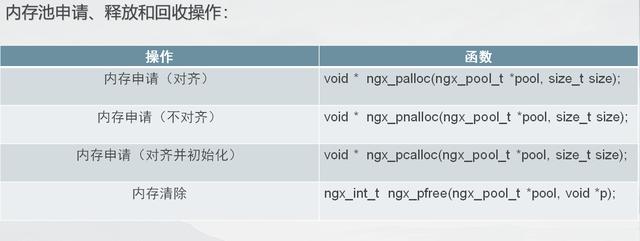
函数原型以及功能叙述
//函数申明
mp_pool_s *mp_create_pool(size_t size);//创建内存池
void mp_destory_pool( mp_pool_s *pool);//销毁内存池
void *mp_alloc(mp_pool_s *pool, size_t size);
//从内存池中申请并且进行字节对齐
void *mp_nalloc(mp_pool_s *pool, size_t size);
//从内存池中申请不进行字节对齐
void *mp_calloc(mp_pool_s *pool, size_t size);
//模拟calloc
void mp_free(mp_pool_s *pool, void *p);
void mp_reset_pool(struct mp_pool_s *pool);
//重置内存池
static void *mp_alloc_block(struct mp_pool_s *pool, size_t size);
//申请小块内存
static void *mp_alloc_large(struct mp_pool_s *pool, size_t size);
//申请大块内存对应nginx函数原型

重点函数分块细节刨析
mp_create_pool: 创建线程池
第一块内存: 大小设置为 size + sizeof(node) + sizeof(pool) ?
mp_node_s head[0] 啥意思?
mp_pool_s* mp_create_pool(size_t size) {
struct mp_pool_s *p = NULL;
int ret = posix_memalign((void **)&p, MP_ALIGNMENT, size + sizeof(mp_pool_s) + sizeof(mp_node_s));
if (ret) {
return NULL;
}
//内存池小块的大小限制
p->max = (size < MP_MAX_ALLOC_FROM_POOL) ? size : MP_MAX_ALLOC_FROM_POOL;
p->current = p->head;//第一块为当前块
p->large = NULL;
p->head->last = (unsigned char *)p + sizeof( mp_pool_s) + sizeof(mp_node_s);
p->head->end = p->head->last + size;
p->head->failed = 0;
return p;
}看完了代码来回答一下问题
- 为了尽可能地避免内存碎片地产生, 小内存地申请, 于是我采取地方式是将 memory pool内存池也放入到首块内存中地方式. 同时所有地node结点信息也都统一存储在每一个内存块中.
- head[0] : 是一种常用于变长结构体地技巧, 不占用内存, 仅仅只是表示一个地址信息, 存储head node 的地址.
mp_alloc 带字节对齐的内存申请
首先按照size大小选择内存分配方式, 小于等于线程池小块最大大小限制就从已有小块中申请, 小块不足就调用mp_alloc_block创建新的小块 否则就调用 mp_alloc_large 申请创建一个大块内存
mp_align_ptr 用于字节对齐
void *mp_alloc(mp_pool_s *pool, size_t size) {
mp_node_s* p = NULL;
unsigned char* m = NULL;
if (size <= MP_MAX_ALLOC_FROM_POOL) {//从小块中分配
p = pool->current;
do {//循环尝试从现有小块中申请
m = mp_align_ptr(p->last, MP_ALIGNMENT);
if ((size_t)(p->end - m) >= size) {
p->last = m + size;
return m;
}
p = p->next;
} while (p);
//说明小块中都分配失败了, 于是从新申请一个小块
return mp_alloc_block(pool, size);
}
//从大块中分配
return mp_alloc_large(pool, size);
}mp_alloc_block 申请创建新的小块内存
psize 大小等于mp_node_s结点内存大小 + 实际可用内存块大小
搞清楚内存块组成:结点信息 + 实际可用内存块
返回的内存是实际可用内存的起始地址
//申请小块内存
void *mp_alloc_block(struct mp_pool_s *pool, size_t size) {
unsigned char* m = NULL;
size_t psize = 0;//内存池每一块的大小
psize = (size_t)((unsigned char*)pool->head->end - (unsigned char*)pool->head);
int ret = posix_memalign((void**)&m, MP_ALIGNMENT, psize);
if (ret) return NULL;
//此时已经分配出来一个新的块了
mp_node_s* new_node, *p, *current;
new_node = (mp_node_s*)m;
new_node->end = m + psize;
new_node->failed = 0;
new_node->next = NULL;
m += sizeof(mp_node_s);//跳过node
//对于m进行地址起点内存对齐
m = mp_align_ptr(m, MP_ALIGNMENT);
new_node->last = m + size;
current = pool->current;
//循环寻找新的可分配内存块起点current
for (p = current; p->next; p = p->next) {
if (p->failed++ > 4) {
current = p->next;
}
}
//将new_node连接到最后一块内存上, 并且尝试跟新pool->current
pool->current = current ? current : new_node;
p->next = new_node;
return m;
}mp_alloc_large 申请创建新的大块内存
大块内存参考nginx_pool 采取采取的是malloc分配
先分配出来所需大块内存. 在pool的large链表中寻找是否存在空闲的alloc. 存在则将内存挂在上面返回. 寻找5次还没有找到就另外申请一个新的large结点挂载内存, 链接到large list中管理
mp_large_s* node 是从内存池中分配的, 也就是从小块中分配的 why? 减少内存碎片, 将大块的node信息放入小块内存中,避免小内存的申请, 减少内存碎片
留疑? 空闲的alloc从何而来?
void *mp_alloc_large(struct mp_pool_s *pool, size_t size) {
void* p = malloc(size);
if (p == NULL) return NULL;
mp_large_s* l = NULL;
size_t cnt = 0;
for (l = pool->large; l; l = l->next) {
if (l->alloc) {
l->alloc = p;
return p;
}
if (cnt++ > 3) {
break;//为了提高效率, 检查前5个块, 没有空闲alloc就从新申请large
}
}
l = mp_alloc(pool, sizeof(struct mp_large_s));
if (l == NULL) {
free(p);
return NULL;
}
l->alloc = p;
l->next = pool->large;
pool->large = l;
return p;
}空闲的alloc是被free掉了空闲出来的. 虽然nginx采取的是小块不单独回收, 最后统一回收, 因为小块的回收非常难以控制, 不清楚何时可以回收. 但是对于大块nginx提供了free回收接口.
mp_free_large 回收大块内存资源
void mp_free_large(mp_pool_s *pool, void *p) {
mp_large_s* l = NULL;
for (l = pool->large; l; l = l->next) {
if (p == l->alloc) {
free(l->alloc);
l->alloc = NULL;
return ;
}
}
}整体代码附下
#ifndef _MPOOL_H_
#define _MPOOL_H_
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include <fcntl.h>
#define MP_ALIGNMENT 32
#define MP_PAGE_SIZE 4096
#define MP_MAX_ALLOC_FROM_POOL (MP_PAGE_SIZE-1)
#define mp_align_ptr(p, alignment) (void *)((((size_t)p)+(alignment-1)) & ~(alignment-1))
//内存起点对齐
typedef struct mp_large_s {
struct mp_large_s* next;
void* alloc;//data区
} mp_large_s;
typedef struct mp_node_s {
unsigned char* last;//下一次内存分配的起点
unsigned char* end;//当前内存块末尾
size_t failed;//当前内存块分配失败的次数
struct mp_node_s* next;
} mp_node_s;
typedef struct mp_pool_s {
mp_large_s* large;//指向大块内存起点
mp_node_s* current;//指向当前可分配的小内存块起点
int max;//小块最大内存
mp_node_s head[0];//存储地址, 不占据内存,变长结构体技巧
//存储首块小内存块head地址
} mp_pool_s;
//函数申明
mp_pool_s *mp_create_pool(size_t size);//创建内存池
void mp_destory_pool( mp_pool_s *pool);//销毁内存池
void *mp_alloc(mp_pool_s *pool, size_t size);
//从内存池中申请并且进行字节对齐
void *mp_nalloc(mp_pool_s *pool, size_t size);
//从内存池中申请不进行字节对齐
void *mp_calloc(mp_pool_s *pool, size_t size);
//模拟calloc
void mp_free(mp_pool_s *pool, void *p);
void mp_reset_pool(struct mp_pool_s *pool);
//重置内存池
static void *mp_alloc_block(struct mp_pool_s *pool, size_t size);
//申请小块内存
static void *mp_alloc_large(struct mp_pool_s *pool, size_t size);
//申请大块内存
mp_pool_s* mp_create_pool(size_t size) {
struct mp_pool_s *p = NULL;
int ret = posix_memalign((void **)&p, MP_ALIGNMENT, size + sizeof(mp_pool_s) + sizeof(mp_node_s));
if (ret) {
return NULL;
}
//内存池小块的大小限制
p->max = (size < MP_MAX_ALLOC_FROM_POOL) ? size : MP_MAX_ALLOC_FROM_POOL;
p->current = p->head;//第一块为当前块
p->large = NULL;
p->head->last = (unsigned char *)p + sizeof( mp_pool_s) + sizeof(mp_node_s);
p->head->end = p->head->last + size;
p->head->failed = 0;
return p;
}
void mp_destory_pool( mp_pool_s *pool) {
//先销毁大块
mp_large_s* l = NULL;
mp_node_s* p = pool->head->next, *q = NULL;
for (l = pool->large; l; l = l->next) {
if (l->alloc) {
free(l->alloc);
l->alloc = NULL;
}
}
//然后销毁小块内存
while (p) {
q = p->next;
free(p);
p = q;
}
free(pool);
}
//申请小块内存
void *mp_alloc_block(struct mp_pool_s *pool, size_t size) {
unsigned char* m = NULL;
size_t psize = 0;//内存池每一块的大小
psize = (size_t)((unsigned char*)pool->head->end - (unsigned char*)pool->head);
int ret = posix_memalign((void**)&m, MP_ALIGNMENT, psize);
if (ret) return NULL;
//此时已经分配出来一个新的块了
mp_node_s* new_node, *p, *current;
new_node = (mp_node_s*)m;
new_node->end = m + psize;
new_node->failed = 0;
new_node->next = NULL;
m += sizeof(mp_node_s);//跳过node
//对于m进行地址起点内存对齐
m = mp_align_ptr(m, MP_ALIGNMENT);
new_node->last = m + size;
current = pool->current;
for (p = current; p->next; p = p->next) {
if (p->failed++ > 4) {
current = p->next;
}
}
//将new_node连接到最后一块内存上, 并且尝试跟新pool->current
pool->current = current ? current : new_node;
p->next = new_node;
return m;
}
//申请大块内存
void *mp_alloc_large(struct mp_pool_s *pool, size_t size) {
void* p = malloc(size);
if (p == NULL) return NULL;
mp_large_s* l = NULL;
size_t cnt = 0;
for (l = pool->large; l; l = l->next) {
if (l->alloc) {
l->alloc = p;
return p;
}
if (cnt++ > 3) {
break;//为了提高效率, 检查前5个块, 没有空闲alloc就从新申请large
}
}
l = mp_alloc(pool, sizeof(struct mp_large_s));
if (l == NULL) {
free(p);
return NULL;
}
l->alloc = p;
l->next = pool->large;
pool->large = l;
return p;
}
//带有字节对齐的申请
void *mp_alloc(mp_pool_s *pool, size_t size) {
mp_node_s* p = NULL;
unsigned char* m = NULL;
if (size < MP_MAX_ALLOC_FROM_POOL) {//从小块中分配
p = pool->current;
do {
m = mp_align_ptr(p->last, MP_ALIGNMENT);
if ((size_t)(p->end - m) >= size) {
p->last = m + size;
return m;
}
p = p->next;
} while (p);
//说明小块中都分配失败了, 于是从新申请一个小块
return mp_alloc_block(pool, size);
}
//从大块中分配
return mp_alloc_large(pool, size);
}
//不带字节对齐的从内存池中申请内存
void *mp_nalloc(mp_pool_s *pool, size_t size) {
mp_node_s* p = NULL;
unsigned char* m = NULL;
if (size < MP_MAX_ALLOC_FROM_POOL) {//从小块中分配
p = pool->current;
do {
m = p->last;
if ((size_t)(p->end - m) >= size) {
p->last = m + size;
return m;
}
p = p->next;
} while (p);
//说明小块中都分配失败了, 于是从新申请一个小块
return mp_alloc_block(pool, size);
}
//从大块中分配
return mp_alloc_large(pool, size);
}
void *mp_calloc(struct mp_pool_s *pool, size_t size) {
void *p = mp_alloc(pool, size);
if (p) {
memset(p, 0, size);
}
return p;
}
void mp_free(mp_pool_s *pool, void *p) {
mp_large_s* l = NULL;
for (l = pool->large; l; l = l->next) {
if (p == l->alloc) {
free(l->alloc);
l->alloc = NULL;
return ;
}
}
}
#endif

如若转载,请注明出处:https://www.daxuejiayuan.com/20667.html
相关推荐
-
win系统大全(数控系统大全)
这篇文章是HTTPS://wiki.osdev.org/Projects页面的翻译。 英文好的可以直接看原网页。这个是我偶然发现的网站,我惊讶于这里竟然有如此多的操作系统的源码。既…
-
电商平台排行榜前十名(电商是做什么的)
记者 | 程璐 编辑 | 3月以来,随着疫情在全国范围内的蔓延,多地快递物流都受到了不同程度的影响。物流是保证电商生态正常运转的关键通道,一旦流通受阻,必然引发一系列连锁效应——商…
-
企业系统管理软件有哪些(正点云企业系统管理)
在企业经营中,必须建立的十二个管理系统 企业管理系统的作用 企业在经营管理中,遇到最大的问题就是效率低、品质差、客户投诉多、没有利润,致使企业经营越来越困难,直至倒闭。这是因为企业…
-
开放源代码软件(开放源代码的网络操作系统是)
也许每个人都或多或少地存在这样或那样的小秘密:有的我们不愿意对别人说,有的我们乐意和最亲近的人说。 这些秘密虽属于我们和朋友们,却常常不能激起多大的波澜。因此,我们通常会将它藏起来…
-
114啦网址导航建站系统(114啦网址导航官网还运行)
上海市民熟悉的“辫子车”20路今天迎来了自己114周岁的“生日派对”,这也是一场为即将“退役”的青年车型举办的“告别派对”,新车有望今年上半年上线投用,吸引许多电车迷们前来打卡。此…
-
中国免网idc(中国免网怎么样)
曾几何时,在宽带市场还没有中国移动的时候,电信为主导者,那时候的宽带一年一两千块,网速最高12M,安装费从最初的0元涨到200,铜猫从0元涨到200,加起来399. 要便宜智能去拉…
-
车家号(车家保是什么保险)
哈喽,大家好!检车家又和大家见面啦,因为我长得显老所以都调侃叫我黎叔,久而久之也就习惯了,其实我还是个花季少年。欢迎大家收看本期二手车检测趣事。我是一名修过车的二手车检测师,更是一…
-
电子商务网站模板(电子商务电子版)
XXX分公司直播赋能 构建农村电商新业态 XXXX分公司于X月X日开展“大牌价到”TOP大单品直播活动,活动主推品牌为XXXX。直播间累计观看掌柜数XXX人,优质站点参与率XXX%…
-
光线cms建站系统(光线cms安装视频)
不少人可能会有一个固定的印象:CMS不就是做网站使用的吗?其实并不是的。CMS,是内容管理系统,因为以前主要是网站才用到这个,所以大家会默认称为:“网站内容管理系统”,而现在,并不…
-
江湖娱乐公司(江湖娱乐幺子分游戏下载)
1.王俊凯确实因为疑似虚假代言的事情受到了点影响,有几个刚接触的资源危险了。 2.杨幂和女儿打电话,经常没说几句就挂了,主要太久没见面,母女俩压根不知道聊什么,只能尴尬地挂电话了。…
