
大家好,我是公众号3分钟学堂的郭立员~
这两天群友接了一单定制脚本的活,采集500彩票网的开奖数据,具体细节我没问,通过问我的问题,我猜猜采集的数据可能是这个:
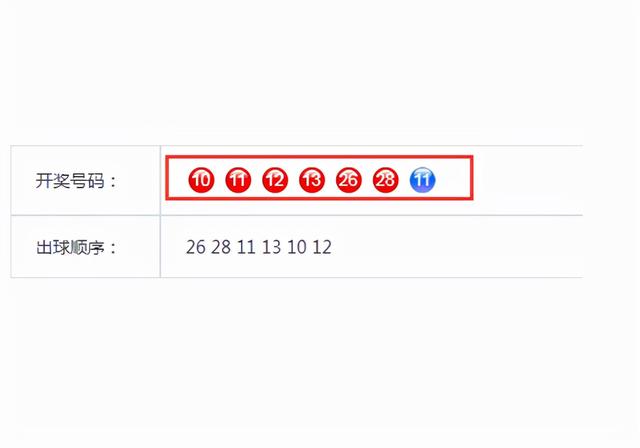

采集的目标网址:https://kaijiang.500.com/shtml/ssq/03001.shtml
遇到的问题是啥呢?
使用按键直接获取网页源码得到的结果是这样的:
TracePrint url.get("https://kaijiang.500.com/shtml/ssq/03001.shtml")当前脚本第1行:<html>
<head><title>301 Moved Permanently</title></head>
<body bgcolor="white">
<center><h1>301 Moved Permanently</h1></center>
<hr><center>nginx</center>
</body>
</html>
返回的结果是301重定向(并不是报错),无法获取到网页的html源码,我用浏览器自带的抓包调试工具看了一下,也没有跳转到别的网址,猜测是网页为了限制爬虫采集,做了一个假的跳转。
因为浏览器可以正常访问页面,所以想到的方法就是伪装成浏览器获取网页源码。
说是伪装,其实就是在http请求头里面加上User-Agent参数,很多做过抓包协议的人都懂的。
这个文章就这么一个知识点,直接上源码:
Import "shanhai.lua"
Dim uri = "https://kaijiang.500.com/shtml/ssq/03001.shtml"
Dim hader = "Mozilla/5.0 (Windows NT 6.1; Win64; x64) Apple WebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36"
Dim date1 = {"url":uri,"code":"gb2312", "cookie":"", "header":{"User-Agent":hader}}
Dim login = Url.HttpPost(date1)
TracePrint login
Dim arr=shanhai.RegexFind(login,"<li class=""ball_.-"">(.-)</li>")
For Each k In arr
TracePrint k
Next
Dim haoma=shanhai.RegexFind(login,"出球顺序:.-<td>(.-)<")
TracePrint haoma(0)还有一点需要注意的,网站编码是GB2312,所以HttpPost命令的code需要修改一下,否则网页中汉字部分会出现乱码。
=正文完=


如若转载,请注明出处:https://www.daxuejiayuan.com/13124.html
相关推荐
-
114股票网址导航(股票网址导航360)
大家好,我是金融小猎人。炒股像打猎,先认识猎物,再练就打猎的硬功夫,外加顺手工具。一旦猎物出现,坚决扣动板机。 今天分享,进入股市需要掌握的必备知识。 00 引言 股市知识纷繁复杂…
-
天下有情人下载周华健齐豫 百度网盘(天下有情人下载 MKV 下载)
2022年你是否还单着 想不想找个人一起过 孤单日子过得没法说 孤单的往事随风过 孤单人啊特别多 真心对待的没有了几个 逢场作戏的就别打扰了 人生的旅途风雨多 错过的路过的不要问为…
-
钟点清洁工情况说明(钟点清洁煮饭阿姨)
还不如在老家种瓜,收麦,打菜籽 。 这正是夏季双抢农忙的季节,乡下有忙不完的活。 而我在这里除了做核酸就是做核酸。 大好时光都被浪费了。 今年千不该万不该来北京。 现在连自己都养不…
-
群发邮件软件源码(群发邮件软件哪个好)
在日常办公中我们发现,如果你是一名HR,你可能需要每个月定时通过邮箱发送每一位员工的工资条,如果你是一名老师,你可能需要每学期通过邮箱将每一位同学的成绩发送到对应家长邮箱。 如果是…
-
飘零网站(飘零 下载)
#头条故事会# 《飘零》 岁月依旧红颜老, 涕泪纵横冷青衫。 试问故人愁何在, 落絮满天飞雪寒。 中篇小说《秋叶的飘零》是以真实爱情故事为原型改编而成的一部爱情小说。 作者舞清影用…
-
办公软件大全(办公应用软件)
如果我没猜错,每个打工人的梦想都是准时下班! 所以今天,我就给大家分享6款电脑必装的办公软件。款款都是效率神器,让你的工作效率瞬间翻倍,每天都能准时下班!!! 1.Quicker这…
-
商城网站模板购买(商城网站模板商城网站)
用模板开发商城比较好还是定制开发比较好,对于准备建商城的朋友来说,选择困难又犯了,其实你只要相信适合自己的才是最好的,就很好选了。 定制开发商城需要的花费,不用说肯定比模板开发要多…
-
xp系统下载站(XP如何安装微信电脑版)
XP系统如何安装电脑版微信呢?对于还在使用xp系统的网友来说可能不知道如何操作,其实方法不会有多难,和其它系统基本没有区别,这里就给大家分享一下操作步骤吧。 系统:xp系统 电脑:…
-
广西住建厅考试培训系统(云南省反假从业人员考试培训系统)
国企事业单位:不论是干部还是基层,用答题小博士抓起培训,用知识武装头脑! 某国企事业单位1 使用需求:操作简单,系统稳定,能够满足高并发远程培训 使用场景:防疫知识培训 解决方案:…
-
网站链接禁止访问怎么办(网站链接怎么复制)
分享8个实用的在线网址 第一个:在线markdown 网址:https://www.liuchengtu.com/markdown/ 它是一个在线编辑工具,可以在线编写文档、画思维…